cuda_learning_03
cuda_learning_03
1. 前置知识
1.1.硬件基础
1.1.1 算计
查询网站:https://www.techpowerup.com/gpu-specs/

1.1.2 带宽

1.2 Warp divergence
三元表达式不会造成线程束分化说是。
1.3 异步复制
可以认为是一种访存方式,指的是__pipeline_memcpy_async()。好处是不使用中间寄存器有助于减少寄存器压力,并可能增加内核占用率。

但是感觉完全可以被cp.async这个ptx指令代替,或者说两者本质是一个东西。后续只会用到cp.async。
1.4 具体问题
$C = αAB + βC$
其中,A的形状是[M, K],B的形状是[K, N],C的形状是[M,N]。为了方便,通常取α = 1,β = 0。
2. Sgemm
Sgemm的优化,包括4个版本的代码和简要分析,具体分析涉及很多详细的计算分析见Reference。
2.1 CPU实现和naiveSgemm
1 | // cpu 实现 |
1 | // 朴素的 GPU 实现 |
NVIDIA GeForce RTX 3090的执行结果如下,理论算力$FP32 (TFLOPS)=CUDA 核心数 × 加速频率 × 2$,计算得10,496×1.70×2=35.7 TFLOPS。该方法算力利用率仅有4.5%。
1 | M N K = 128 128 1024, Time = 0.00008499 0.00008908 0.00009715 s, AVG Performance = 376.6978 Gflops |
这个方法的计算访存比非常低,并且存在大量冗余的全局内存访问。
2.2 矩阵分块并利用Shared Memory和Registers(v1)
上面提到了naiveSgemm的问题,GPU对Shared Memory和Registers是高于Global Memory的,所以可以利用Shared Memory和Registers作为一个类似于cache的效果,并提高计算访存比,这是一个容易想到的角度,具体要如何做,接下来简要说明。

核心目标可以认为是提高计算访存比,具体矩阵分块如上图(图片来源)。下面详细分析一下线程块等具体的大小选择。
对于每一个分块:
计算量:$BM \times BN \times K \times 2$
访存量:$(BM + BN) \times K \times 4 Byte$
计算访存比:$\frac{BM \times BN}{2(BM + BN)} = \frac{1}{2(\frac{1}{BN} + \frac{1}{BM})}$
由上式可知BM和BN越大,计算访存比越高,性能就会越好。但是由于 Shared Memory 容量的限制(3090 1个SM大致96KB),而一个Block需要占用 $BK \times (BM + BN) \times 4 Bytes$大小。
TM和TN的取值也受到两方面限制,一方面是线程数的限制,一个Block中有$\frac{BM}{TM} \times \frac{BN}{TN}$个线程,这个数字不能超过1024,且不能太高防止影响SM内Block间的并行;另一方面是寄存器数目的限制,一个线程至少需要TM * TN个寄存器用于存放矩阵 C 的部分和,再加上一些其它的寄存器,所有的寄存器数目不能超过256,且不能太高防止影响SM内同时并行的线程数目。
最终选取 BM = BN = 128,BK = 8,TM = TN = 8,则此时计算访存比为32。3090的理论算力35.7TFLOPS,理论带宽是936.2 GB/s。不过实测算力在30TFLOPS左右,实测带宽在789GB/s左右,所以我认为应该以这两个数据为标准。此时 30TFLOPS/32 = 938GB/s,带宽多少还是会限制计算性能,但已经好很多了。
关于为什么沿着k维度切成更小的bk,而不是A沿m切,B沿n切?
因为这样切可以保证每个小A分块和小B分块只会加载一次。
按理说有一个中间优化,就是其他不变,但是每个线程还是只计算一个元素,而不是Tm * Tn。一个线程计算Tm * Tn个原因是:可以减少对shared memory的访存量。
其实这一步的优化除了提高了计算访存比,使用更快的Shared Memory和Registers,还有涉及到提高硬件利用率的角度(原本一个线程计算一个数据,现在计算Tm * Tn个,即中间优化提到的)。
根据以上分析,kernel函数实现主要包括以下步骤:
从Global Memory加载对应的矩阵分块到Shared Memory中。
每个线程刚好负责A矩阵的4个元素和B矩阵的4个元素,刚好可以用
FLOAT4来操作,分配好每个线程负责的元素即可。计算对应的C矩阵
写回Global Memory
1 | // 矩阵分块、Shared Memory、Registers |
计算结果如下,性能达到了理论峰值的54.5%,达到了实际可达峰值的63.3%:
1 | M N K = 128 128 1024, Time = 0.00019149 0.00019769 0.00020950 s, AVG Performance = 169.7357 Gflops |
2.3 解决 Bank Conflict 问题(v2)
2.3.1 LDS.32
假设一个warp现在被调度了,它的32个thread此刻要去SMEM上读数。warp发送了一个LDS.32的指令(意思是让所有的thread都取1个数,其大小为4byte,换算成bit就是32)。此时,在cuda的运算中有如下规定:
- 一个warp发送1次取数指令(不一定是LDS.32),它最多只能从SMEM上读取128bytes(32个数)的数据。这是每个warp发送1次取数指令的能取到的数据量上限。
- 如果每个thread要取的数,来自不同的bank,我们就认为没有bank conflict。warp发送1次指令,所有的threads即可取回自己想要的数据。
- 来自同一个bank,但是是这个bank上的同一个数(同一个bank的相同地址,或者说是相同layer),此时也没有bank conflict(广播机制),也是1次指令。
- 如果某些threads要取的数,来自同一个bank,并且是这个bank上的不同数(同一个bank的不同地址,即不同layer),此时发生了bank conflict。同个warp内的threads想要访问同一个bank下的n个不同的地址,就发生了n-way bank conflict(n头bank conflict)。本该1次指令取回的数,就需要串行发送n次指令。
2.3.2 为什么要对SMEM做bank划分
简单来说,为了均衡banks的路宽,为了warp间尽量并行,不要相互阻碍。
2.3.3 LDS.64和LDS.128
LDS.64指令:一次取8bytes的数,即连续的2个数。
LDS.128指令:一次取16bytes的数,即连续的2个数。
以LDS.128为例,一个warp需要取128个数,超过了warp单次memory transaction允许的取数上限。所以该warp会把取数过程拆成4个串行的phase(即4次串行的memory transcation):即0~7,8~15,16~23,24~31。这时bank conflict被定义在每个phase(也就是1/4个warp之内)。
接下来,我们分析v1中是否存在bank冲突。
1 | for(int k = 0; k < BK; ++k) |
一个简单且不太严谨的对s_b的访问分析,每个线程需要访问s_b的连续8个元素。那么tid = 0的线程,访问bank_id 为 0,1,2,3,4,5,6,7;tid = 1的线程,访问bank_id 为 8,9,10,11,12,13,14,15;这样的话,就会发现tid = 0和tid = 4的线程访问的bank正好相同,所以存在一个8路bank conflict。
如果使用FLOAT4,你会发现对s_b的访问存在2路bank conflict,解决方法是把每个线程负责的计算的元素修改一下,让每个线程读取两次连续的4个数,而不是连续的8个数。以上面的图片为例,V1中每个线程块负责计算128*128的子矩阵,每个线程负责计算8*8的子矩阵,线程块大小是16*16。V2中每个线程负责4个4*4的子矩阵,即把128*128的子矩阵分成4个64*64的子矩阵(左上、右上、左下、右下),每个线程负责的那4个4*4子矩阵在这4个64*64的子矩阵的对应位置。
对于s_a的访问,v1中不存在bank conflict,因为触发了广播机制。但是v1中的访问方式无法使用FLOAT4,因为对s_a的访问是不连续的,解决办法是转置。
1 | // 解决 bank conflict |
计算结果如下,性能达到了理论峰值的68.6%,达到了实际可达峰值的80%:
1 | M N K = 128 128 1024, Time = 0.00017306 0.00017603 0.00017715 s, AVG Performance = 190.6225 Gflops |
2.4 流水并行化:Double Buffering(v3)
之前的方法存在 访存-计算 的串行模式流水线,这个方法就是提高访存和计算的并行程度,下图很形象,图片来源。
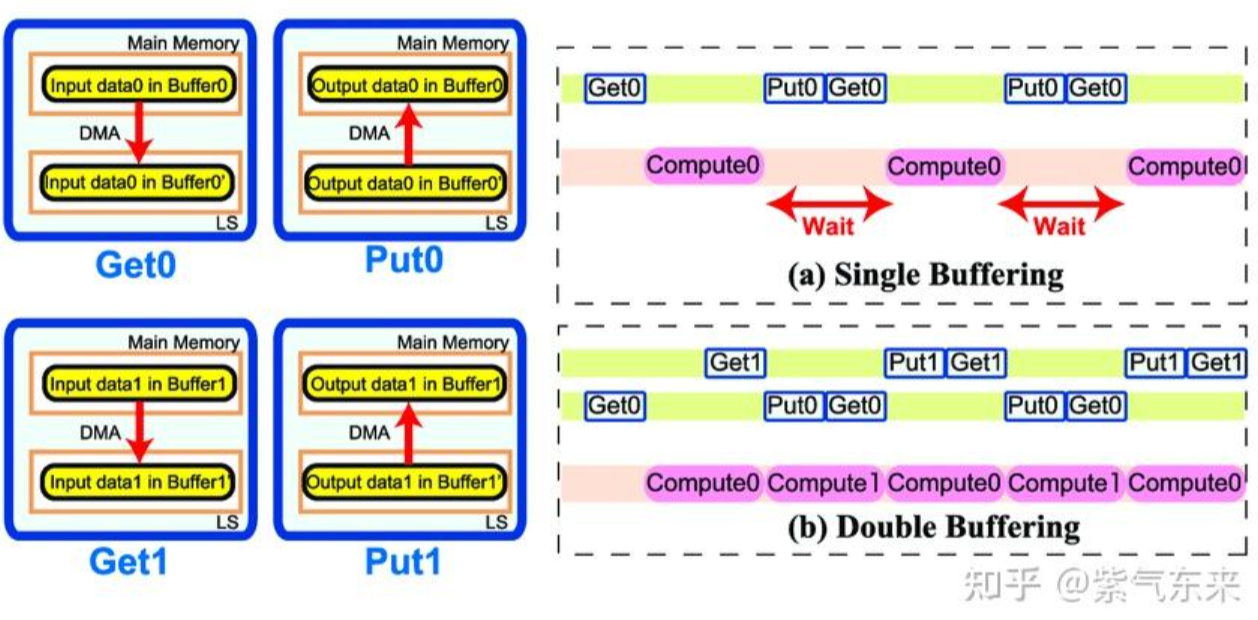
具体到代码实现中,主要有一下几个点:
- 需要原来两倍的Shared Memory
- 第一次加载数据在主循环之前,最后一次计算在主循环之后,主循环从 k = 1开始
- 由于计算和下一次访存使用的Shared Memory不同,因此主循环中每次循环只需要一次__syncthreads()
- GPU不能像CPU那样支持乱序执行,主循环中需要先将下一次循环计算需要的数据从Gloabal Memory中load 到寄存器,然后进行本次计算,之后再将load到寄存器中的数据写到Shared Memory,这样在LDG指令向Global Memory做load时,不会影响后续FFMA及其它运算指令的 launch 执行,也就达到了Double Buffering的目的。
关于第四个点,还是挺深奥的,涉及GPU指令的流水线化和异步内存访问。一开始,我在想,既然GPU不能乱序执行,那么不还是串行吗?实则不然。答案如下,懒得自己总结了。

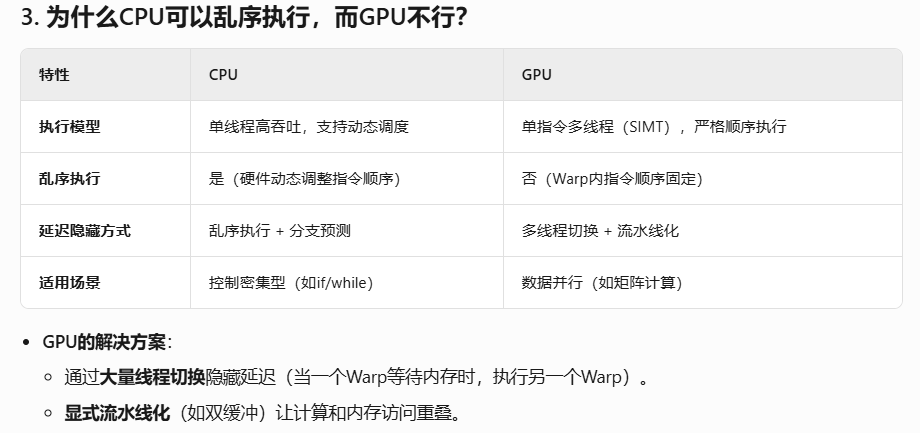
还有一个问题就是LDG是异步的话,那么会不会存在数据竞争导致错误呢?
答案是不会。硬件会自动插入依赖屏障,保证正确性。类似于CPU的load指令可以乱序执行,但编译器/硬件会保证数据依赖的正确性。
1 | // 流水并行化:Double Buffering |
计算结果如下,性能达到了理论峰值的75.7%,达到了实际可达峰值的90%:
1 | M N K = 128 128 1024, Time = 0.00011162 0.00011725 0.00012186 s, AVG Performance = 286.1834 Gflops |
2.5 cuBLAS 性能
性能达到了理论峰值的83.9%,实际可达峰值的99%:
1 | M N K = 128 128 1024, Time = 0.00001843 0.00035505 0.00335494 s, AVG Performance = 94.5063 Gflops |
3. Hgemm
半精度浮点类型的矩阵乘法,使用tensor core。
3.1 前置知识
3.1.1 cublas的调用
cublas有个诡异的列优先原则,导致这个函数接口的传参不是那么容易,要好好注意这个是否转置、两个矩阵的顺序、主维等参数。给出两种方法:
1 | //第一种:诡异先b再a |
第二种:喜欢转置说是
两种都能求的正确结果,但是明显方法1更好,因为不用转置,毕竟矩阵大了的话,转置需要的时间也不小。参考blog:有关CUBLAS中的矩阵乘法函数 - 爨爨爨好 - 博客园
3.1.2 tensor core api
这里我们以D = A * B + C 为例。
1 | // 着重注意第一个参数和最后一个参数 |
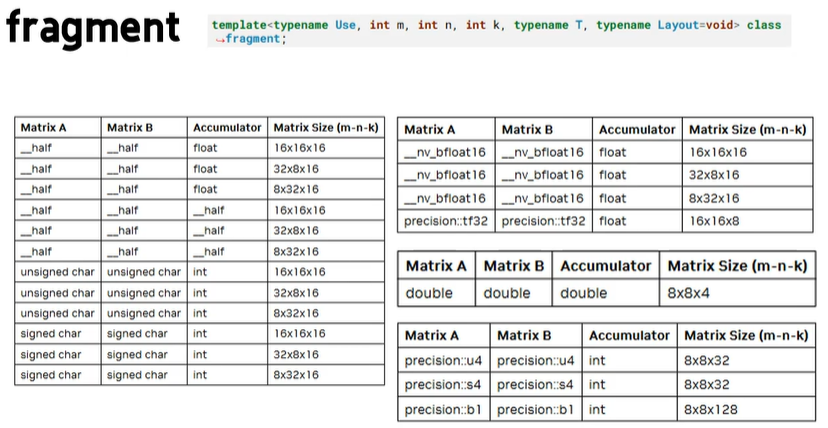
3.1.3 ptx 指令
ldmatrix
1
2
3
4
5
6
7
8
9
10LDMATRIX_X1:加载一块8x8的半精度(b16)矩阵tile(通常为Tensor Core的数据载入方式)从shared memory 到单个寄存器(R)。
ldmatrix:矩阵块加载PTX指令.sync.aligned:同步、对齐方式.x1:一次加载1个tile(8x8).m8n8:tile大小8x8.shared.b16:从shared memory以16位为单位加载(每 16 位为一个数据元素).x2:每次加载2个tile.x4:每次加载4个tile
HMMA16816
1
2
3
4mma:矩阵-矩阵累加(Matrix Multiply Accumulate)PTX指令.sync.aligned:同步、对齐.m16n8k16:矩阵维度(MxN乘K).row.col:内存布局(行主序/列主序)f16.f16.f16.f16:操作数和结果全为半精度float16- 输出:
{%0, %1}:结果D的两个寄存器
- 输入:
RA0~RA3、RB0~RB1:A和B矩阵块的寄存器RC0, RC1:累加用的C寄存器
CP_ASYNC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19CUDA 11.4 及以上:
cp.async:CUDA 8.0+ 新增的异步数据拷贝PTX指令(copy async),用于把全局内存数据异步搬到 shared memory。ca:cache all(全层缓存提示),告诉硬件这次搬运要经过所有缓存。cg:cache global(只缓存到 L1,跳过 L2)。.L2::128B:新语法,指明此次操作对 L2 cache 的控制方式(128 字节对齐/搬运),增加细粒度 cache 控制(11.4 新特性)。shared.global:从全局内存搬到共享内存。[%0]:目标 shared memory 地址(dst)。[%1]:源全局内存地址(src)。%2:要搬运的字节数(Bytes)。
CUDA 11.3 及一下:只是没有
.L2::128B后缀。因为11.4之前 PTX不支持L2 cache细粒度控cp.async.commit_group:告诉GPU,在这之前的cp.async属于一组,并不是到这条命令的时候才会开始运行,之前就开始了。cp.async.wait_group %0:等待一个 已提交的异步拷贝操作组 完成。类似于 CUDA 的 __syncthreads(),但仅针对异步拷贝操作,而不是全部线程同步。
关于这些api 和 指令,不如直接看下面有例子,看例子更好理解。
3.2 v1
首先讨论BM等数据的选取,具体数值来源于其他博客的分析。
BM和BN是越大越好,然后打算选取16*16*16的的tensor core,BK至少需要是nvcuda::wmma::fragment中定义矩阵的K维度的整数倍;当BK太小(例如取BK = 16)时,核心循环中HMMA指令占比不高,一些循环相关的地址计算的指令会导致性能下降;当BK >= 32时,发现性能基本不会再随BK而提高了;加之hared memory、Registers的限制,最终取BM = 128,BN = 256,BK = 32,thread_per_block = 256。
这样每次K循环中,256个线程每个线程需要取16个矩阵A的元素,取32个矩阵B的元素;8个warp每个warp负责计算64x32x64的矩阵乘法。为了方便起见假设M/N/K对齐到128/256/32,也就是没有处理corner case。
调用的C++ wmma的API,代码如下:
1 | __global__ void myHGEMMAlignedV1(half * __restrict__ a, half * __restrict__ b, half * __restrict__ c, |
这里有三个疑问,一是每个线程取16个矩阵A的元素,目前是每个线程取相邻两行的连续8列,而不是取一行的16列。关于为什么要这样?
没找到准确的回答,大体上是有利于合并访存、方便后续共享内存布局、WMMA tile加载、更好地支持多warp并行,避免共享内存bank conflict。
二是关于frag_a的填充,发现frag_a的列坐标在增加,而对应读取的s_a是行坐标在+16,这样写是否是出于优化的角度?是否将frag_a的定义改成frag[4][2]更符合语义?
并不是出于优化的角度,只是通常的代码习惯。主流的wmma相关代码习惯是BK方向在前(方便做K方向累加),M/N方向在后,并且方便后面wmma::mma_sync的调用。
三是关于bank confilct的解决,这里是通过加了16 Bytes的pad解决的,为什么能解决?
关于这个,我并没有想明白,这部分对smem的读取是warp协作读取的,我不会确定每个线程读取哪些数据,但是它应该是确实能避免的,并且这似乎也是一种官方常用方式。
3.3 Hgemm v2: Global Memory到Shared Memory的异步拷贝
对全局内存的访问通过异步拷贝实现,即利用前面提到的cp.async指令,注意smem的首地址要用__cvta_generic_to_shared()获取,具体看代码:
1 | __global__ void myHGEMMAlignedV2(half * __restrict__ a, half * __restrict__ b, half * __restrict__ c, |
3.4 v2: Double Buffer
Sgemm中详细介绍过,不多废话了,需要注意的是double buffer会用到两倍的shared memory,当使用的shared memory超过48 KB时,需要使用dynamic shared memory。kernel的怕配置和调用方式如下:
1 | const int BM = 128, BN = 256, BK = 32; |
1 | __global__ void myHGEMMAlignedV3(half * __restrict__ a, half * __restrict__ b, half * __restrict__ c, |
3.5 v4: 提高L2 Cache的局部性
RTX3090一共有82个SM,经过计算v3的优化,每个SM只能容纳一个block,当大规模矩阵乘法的block数目超过82时,会按照gridDim.z -> gridDim.y -> gridDim.x这样的循环顺序进行调度。
例如当M = N = K = 16384时,矩阵C会被分块成128 * 64个Tile,如果按照正常的调度顺序,先调度矩阵C第一行64个Tile对应的block加上第二行的前18个block,这样虽然矩阵A的局部性很好,但是矩阵B的访存局部性极差。所以考虑平衡矩阵A和矩阵B的局部性,现在改成第一次先调度第一行到第五行的前16个block,加上第六行的前2个block。
主要需要做的是修改一下调用kernel时的代码,利用其默认的调度顺序,加上gridDim.z这一维,这里NSPLIT就代表矩阵C的一行一次调度NSPLIT列就改转到下一行(NSPLIT = 16 * 256 = 4096):
1 | const int BM = 128, BN = 256, BK = 32; |
1 | __global__ void myHGEMMAlignedV4( |
3.6 v5: 循环展开
主要修改是显式要求编译器对循环完全展开32次(如果 K/BK 比32大,则只会unroll前32次),没有显式的 #pragma unroll,即让编译器默认决定是否展开循环。
1 | __global__ void myHGEMMAlignedV5( |
关于hgemm这部分的性能,可以参考这篇文章的情况,实测和文中相差不大,v5最后最好的情况下达到了140TFLOPS。
4. 最后
代码仓库:神秘链接
3090上sgemm性能最好大约在27TFLOPS左右,cublas在30TFLOPS左右,达到了90%左右的性能,2080ti上cublas和sgemm的最好性能都在11TFLOPS,接近99%的性能。
hgemm的话由于用了cp.async指令,只能在3090(sm_80)上跑,2080ti(sm_75)不支持,最好性能140TFLOPS左右,平均大概在130TFLOPS左右,cublas基本稳定在130TFLOPS之上,最好性能也在140TFLOPS左右。