OpenCL 入门
OpenCL 入门
openCL基本概念
1.平台(Platform)
OpenCL平台是指支持OpenCL的硬件和驱动程序的集合。一个平台通常包括多个计算设备(例如CPU和GPU),以及运行OpenCL程序的驱动程序和工具。每个平台包含一个OpenCL实现,可能是由不同的硬件厂商(如NVIDIA、AMD、Intel)提供的。
2.设备(Device)
OpenCL设备是指实际执行OpenCL计算任务的硬件。例如,CPU、GPU、FPGA等都可以作为OpenCL设备。
3. 上下文(Context)
OpenCL上下文是一个运行OpenCL程序的环境。它包含与平台和设备相关的资源,例如内存对象、编程模型等。上下文负责管理设备之间的协作,处理并发操作,并提供同步机制。(资源管理、任务调度、内存管理、线程同步)
4.命令队列(Command Queue)
命令队列是OpenCL的一个重要概念,它用于调度和管理计算任务。命令队列存储需要执行的命令(如内存操作、内核执行等),并按照先后顺序执行。每个命令队列只能与一个设备相关联,通常设备会有多个命令队列,以便支持多个任务的并发执行。
5.内核(Kernel)
内核是OpenCL程序的基本单元,是在设备上执行的并行计算任务。内核由OpenCL C语言编写,OpenCL内核函数会在设备的多个计算单元上并行执行,从而实现高效的计算。
6.内存对象(Memory Objects)
内存对象(Memory Objects) 是用于在主机(通常是CPU)和设备(如GPU、FPGA等)之间传输和存储数据的基本构建块。用于高效地管理内存和数据流动,以便并行计算能够顺利进行。例如,Buffer(penCL中最基础的内存对象,用于存储简单的线性数据结构,如数组、向量等)、Image(用于存储图像数据的内存对象。它专门设计用于处理图像类型数据,适用于图像处理、计算机视觉等应用,存储二维或三维图像数据,可以用于像素级的操作,如纹理映射、滤波、图像变换等)。
7. 事件(Event)
OpenCL中的事件机制用于追踪和管理异步操作的状态。事件允许程序员在执行任务时进行同步控制,避免多个操作的竞争和冲突。事件可以与命令队列中的操作相关联,当操作完成时,事件将被触发。
8.工作项(Work-item)和工作组(Work-group)
工作项(Work-item)是OpenCL中最小的并行计算单元,它是内核执行的基本单元。每个工作项在计算时都具有独立的ID,可以在内核函数中使用该ID来确定该工作项的任务。(thread)
工作组(Work-group)是由多个工作项组成的集合。OpenCL将工作项组织为工作组,这些工作组可以并行地在设备上执行,工作组之间的执行是独立的。(block)
openCL与cuda对比
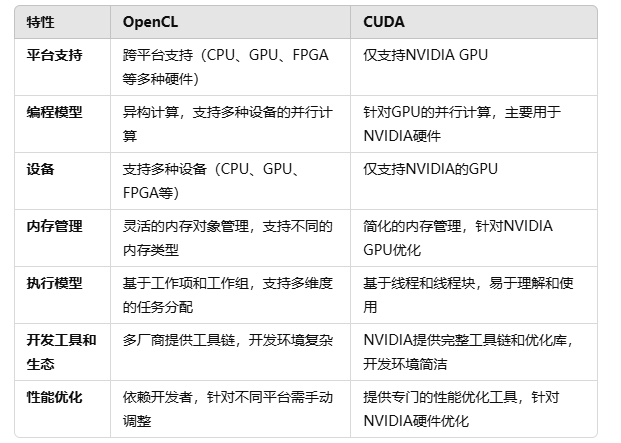
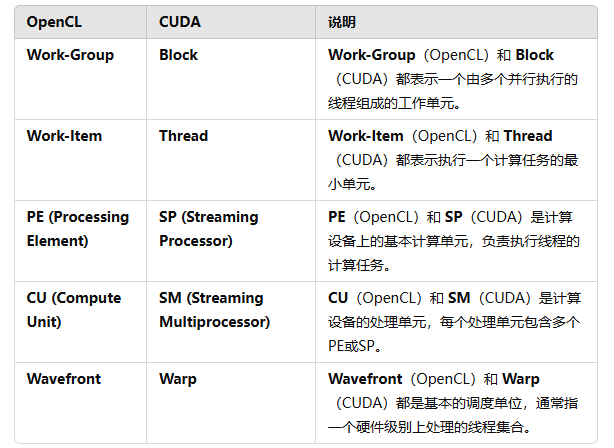
opencl比cuda更底层,跨平台,性能优化方面opencl需要开发者依靠不同的平台来手动调整。
openCL的工作流程
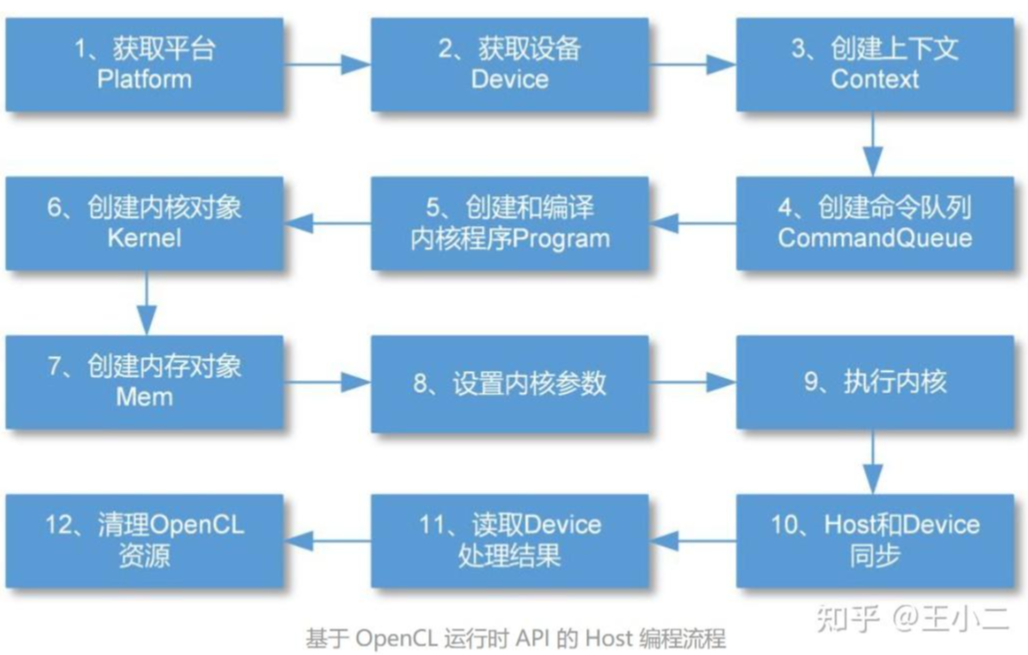
大体流程如下图,opencl比较底层,步骤相较于cuda繁琐。图片来源
1 | //代码流程框架 |
1.平台(Platform)和设备(Device)初始化
- 获取平台
调用clGetPlatformIDs列出可用平台。
函数原型:
1 | cl_int clGetPlatformIDs( |
使用示例
1 | cl_uint num_platforms; |
- 选择设备
每个平台可能有多个计算设备(如不同厂商的GPU或CPU)。使用 clGetDeviceIDs 来列出平台上的设备,选择一个或多个设备来进行计算。
函数原型
1 | cl_int clGetDeviceIDs( |
device_type:指定设备类型,可以是以下几种常见类型:
CL_DEVICE_TYPE_CPU:查询CPU设备。
CL_DEVICE_TYPE_GPU:查询GPU设备。
CL_DEVICE_TYPE_ACCELERATOR:查询加速器设备(如FPGA)。
CL_DEVICE_TYPE_ALL:查询平台上所有设备(包括CPU、GPU和加速器等)。
使用示例
1 | cl_uint num_devices; |
2.创建OpenCL上下文(Context)
上下文 是OpenCL程序执行的环境,它提供了一个运行时环境来管理设备、内存、命令队列等资源。上下文是OpenCL应用的基础,它允许程序与平台上的设备进行交互,并协调多个设备之间的任务。
clCreateContext 是 OpenCL 中创建上下文的主要函数,用于初始化并返回一个新的上下文对象。上下文是与平台和设备交互的基本环境,所有 OpenCL 操作都需要在上下文中执行。
函数原型:
1 | cl_context clCreateContext( |
参数说明:
properties:这是一个指向
cl_context_properties数组的指针,用来设置一些上下文的属性。通常对于大部分情况,传入NULL即可。如果需要为上下文设置特定的属性(比如平台类型、上下文的版本等),可以在这里传入配置项。1
2
3
4
5
6
7
8
9
10void printf_callback(const char *buffer, size_t len, size_t complete, void *user_data)
{
printf("%.*s", len, buffer);
}
cl_context_properties properties[] = {
CL_PRINTF_CALLBACK_ARM, (cl_context_properties)printf_callback, // 启用 printf 调试功能
CL_PRINTF_BUFFERSIZE_ARM, (cl_context_properties)0x100000, // 设置 printf 输出缓冲区大小为 4MB
CL_CONTEXT_PLATFORM, (cl_context_properties)platform_id, // 选择平台
0 // 结束标识符,表示属性数组的结束
};CL_PRINTF_CALLBACK_ARM:设置一个printf输出回调函数,该函数将在设备端的printf输出时被调用。CL_PRINTF_BUFFERSIZE_ARM:设置printf输出的缓冲区大小,这里要求设备为printf调试分配一个 4MB 的缓冲区。CL_CONTEXT_PLATFORM:选择平台。platform_id是通过clGetPlatformIDs获取的一个平台 ID,用于指定上下文所使用的平台。0:这是数组的结束标识符,所有 OpenCL 上下文属性数组都需要以0结束。
devices:- 这是一个设备ID数组,表示在这个上下文中使用的设备。每个设备ID对应一个计算设备(如GPU或CPU)。如果只想使用一个设备,可以将该数组设置为一个包含单个设备ID的数组。
notify:- 这是一个回调函数的指针,当发生错误时会被调用。通常我们可以将它设置为
NULL,不使用回调函数,或者提供一个自定义的回调函数来处理错误通知。
- 这是一个回调函数的指针,当发生错误时会被调用。通常我们可以将它设置为
user_data:- 这是一块指针,允许传递额外的数据给回调函数。它可以是任何类型的数据,通常在回调函数中使用。
errcode_ret:- 这是一个指针,用于返回错误代码。如果上下文创建成功,错误码通常是
CL_SUCCESS;否则会返回对应的错误码。可以通过这个参数来获取创建上下文时可能发生的错误。
- 这是一个指针,用于返回错误代码。如果上下文创建成功,错误码通常是
使用示例:
1 | cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, &err); |
1 | // 创建平台2,设备3的上下文 |
3.创建命令队列(Command Queue)
命令队列是程序与设备交互的主要接口,它控制了多个操作(如内核执行、内存传输、同步操作等)的顺序执行。创建命令队列的函数是 clCreateCommandQueue,作用是创建一个用于发送命令到设备的队列。
函数原型:
1 | cl_command_queue clCreateCommandQueue( |
参数说明:
properties:队列属性,可以是一个由位掩码组成的标志值。常用的标志有:
0:表示默认命令队列。(顺序执行)CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE:启用无序执行模式(非阻塞模式)。CL_QUEUE_PROFILING_ENABLE:启用命令队列的性能分析(profiling)。
使用示例:
1 | cl_command_queue queue = clCreateCommandQueue(context, device, 0, &err); |
4.创建内存对象:缓冲区(Buffer)
用于在主机和设备之间传输数据,clCreateBuffer 是用于创建缓冲区的函数。
函数原型:
1 | cl_mem clCreateBuffer( |
参数说明:
flags:- 缓冲区的标志,指定缓冲区的访问权限。常见的标志有:
CL_MEM_READ_WRITE:表示缓冲区可以被读写(即既可以从主机到设备传输数据,也可以从设备到主机传输数据)。CL_MEM_READ_ONLY:表示缓冲区只能用于读取数据。CL_MEM_WRITE_ONLY:表示缓冲区只能用于写入数据。CL_MEM_COPY_HOST_PTR:表示缓冲区将使用主机端的数据进行初始化,host_ptr参数指向的数据会被复制到缓冲区中。
- 缓冲区的标志,指定缓冲区的访问权限。常见的标志有:
host_ptr:- 这是一个可选的参数,指向主机内存中的数据。如果希望缓冲区在创建时从主机数据中初始化,可以将此参数设置为主机内存的指针。如果为
NULL,则缓冲区不会被初始化。
- 这是一个可选的参数,指向主机内存中的数据。如果希望缓冲区在创建时从主机数据中初始化,可以将此参数设置为主机内存的指针。如果为
使用示例:
1 | // 假设我们要创建一个包含1000个float元素的缓冲区 |
缓冲区的用途:
- 将数据传输到设备:使用
clEnqueueWriteBuffer将数据从主机内存写入缓冲区。
1 | clEnqueueWriteBuffer( |
- 从设备读取数据:使用
clEnqueueReadBuffer从设备读取数据到主机内存。
1 | clEnqueueReadBuffer( |
5. 加载和编译OpenCL内核
(1).编写内核代码
示例代码:对数组中的每个元素进行加法操作。
1 | __kernel void vector_add( |
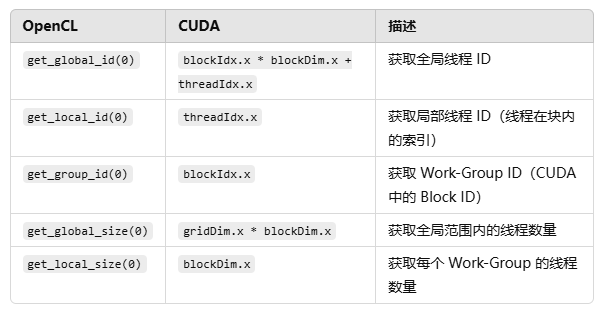
opencl中部分关键字只有左边两个下划线,与cuda不同,关键字的含义基本相同。并且使用get_global_id获取线程索引, OpenCL中Work-Group也是支持多维的,这里的0其实对应cuda中的x。
(2).将内核代码加载到 OpenCL 程序中(创建程序对象)
clCreateProgramWithSource 用于将内核代码加载到 OpenCL 程序中。它接受内核代码的字符串,并在主机上创建一个 OpenCL 程序对象。
函数原型:
1 | cl_program clCreateProgramWithSource( |
示例代码:
1 | const char* kernelSource = "__kernel void vector_add(__global const float* A, __global const float* B, __global float* C, const unsigned int N) { int id = get_global_id(0); if (id < N) { C[id] = A[id] + B[id]; } }"; |
或者将内核函数实现在.cl文件中,在.cpp代码中加载内核函数。
1 | //vector_add.cl |
1 | //main.cpp |
扩展:使用 clCreateProgramWithBinary 将内核代码预编译为二进制文件,运行时直接加载,省去每次编译的时间。
(3).编译内核代码
clBuildProgram 用于将加载的内核代码编译为设备可以执行的二进制格式。
函数原型:
1 | cl_int clBuildProgram( |
参数说明:
options:编译选项,类似于编译器的命令行参数,例如优化级别(-O2)或预处理器定义(-D)。
示例代码:
1 | err = clBuildProgram(program, 1, &device, NULL, NULL, NULL); |
(4).检查编译状态并获取日志(可选)
当 clBuildProgram 失败时,可以使用 clGetProgramBuildInfo 检查编译状态,并获取详细的编译日志。
1 | cl_int clGetProgramBuildInfo( |
参数说明:
- param_name:指定查询的参数,常见的参数包括:
CL_PROGRAM_BUILD_STATUS:编译状态(成功、失败等)。CL_PROGRAM_BUILD_LOG:编译日志。
param_value:保存返回值的指针(例如日志内容)。param_value_size:指定返回值的大小。
示例代码:
1 | size_t log_size; |
6. 创建OpenCL内核对象(Kernel)
调用 clCreateKernel 函数,可以从一个已经成功编译的程序对象中创建内核对象。内核对象将绑定一个具体的内核函数,并用于进一步的设置参数和执行操作。
函数原型:
1 | cl_kernel clCreateKernel( |
示例代码:
1 | cl_kernel kernel = clCreateKernel(program, "vector_add", &err); |
- 确保程序已编译成功:
- 在调用
clCreateKernel之前,必须保证clBuildProgram成功。如果编译失败,clCreateKernel会返回错误。
- 在调用
- 名称匹配:
kernel_name必须与内核源代码中定义的函数名称完全一致。否则会返回CL_INVALID_KERNEL_NAME。
- 多个内核对象:
- 如果一个程序对象包含多个内核函数,可以通过多次调用
clCreateKernel创建对应的内核对象。
- 如果一个程序对象包含多个内核函数,可以通过多次调用
- 清理资源:
- 内核对象是 OpenCL 的资源之一,需要在使用完毕后通过
clReleaseKernel释放。
- 内核对象是 OpenCL 的资源之一,需要在使用完毕后通过
7.设置内核参数
clSetKernelArg 用于设置内核函数的参数。内核的参数必须按照内核代码中声明的顺序和类型逐一设置。
函数原型:
1 | cl_int clSetKernelArg( |
示例代码:
内核函数有多少个参数就需要调用多少次。参数索引也必须和内核函数参数顺序对应。
1 | // 创建缓冲区 |
8. 执行内核
主要包括设置工作项和工作组的大小、将内核提交到设备执行,并等待执行完成。主要需要设置两个参数:
- 全局大小(Global Size):表示工作项的总数(相当于调用的线程总数)。
- 局部大小(Local Size):表示每个工作组中的工作项数(相当于cuda中线程块的大小)。局部大小通常根据硬件的架构进行调整,以优化性能。不同的设备支持不同的局部大小(通常是 32、64、128 或 256 等),局部工作组大小(
local_work_size)通常设置为设备的 warp 或 wavefront 大小(如 32、64、128 等),如果不确定设备支持的最佳大小,可以将其设置为NULL,让 OpenCL 自动选择。
使用 clEnqueueNDRangeKernel 将内核添加到命令队列中并提交给设备执行。
函数原型:
1 | cl_int clEnqueueNDRangeKernel( |
参数说明:
work_dim:工作维度,即表示全局大小和局部大小的维度数。通常是 1、2 或 3。global_work_offset:每个维度的全局偏移量。它指定了全局工作项的起始位置。通常可以设为 NULL,表示没有偏移量,或者设为一个非零值来偏移起始工作项。对于大多数情况,通常设置为 NULL。num_events_in_wait_list:依赖的事件数量。如果当前内核执行需要等待之前的某些操作完成,可以通过事件机制来同步。这个参数表示依赖事件的个数。event_wait_list:依赖事件列表。这个参数指向依赖事件的列表,OpenCL 在执行当前内核之前,会等待这些事件完成。event:内核执行的事件。执行完毕后,OpenCL 会生成一个事件,通知程序内核执行完成。可以在事件上调用clWaitForEvents等函数进行同步。
示例代码:
1 | size_t global_work_size[1] = {N}; |
等待完成
通过调用 clFinish 等待内核执行完成,确保设备执行任务时主机等待。(类似cuda中,主机设备端的同步)
1 | clFinish(queue); |
9. 读取数据
使用 clEnqueueReadBuffer 将设备内存中的数据拷贝到主机内存。
函数原型:
1 | cl_int clEnqueueReadBuffer( |
参数说明:
blocking_read:指定读取操作是否为阻塞操作。CL_TRUE:阻塞模式,主机会等待数据读取完成后继续执行。CL_FALSE:非阻塞模式,数据读取会异步进行,主机可以继续执行其他操作。
offset:指定缓冲区中的偏移量(以字节为单位)。通常设置为0,表示从缓冲区的起始位置读取。num_events_in_wait_list,event_wait_list,event:同clEnqueueNDRangeKernel。
示例代码:
1 | // 从设备读取结果 |
10.清理资源
OpenCL 提供了多个释放函数,用于清理和释放在程序运行期间创建的各种对象,避免出现内存泄漏或资源占用问题。这些函数以 clRelease* 开头。
需要释放的资源:
cl_kernel对象:clReleaseKernelcl_program对象:clReleaseProgramcl_mem对象:clReleaseMemObjectcl_command_queue对象:clReleaseCommandQueuecl_context对象:clReleaseContext
示例代码:
1 | // 等待命令队列中的所有任务完成 |
注意释放顺序,如果上下文被释放,所有依赖于该上下文的对象也会变为无效对象。所以需要按照从依赖最少到依赖最多的顺序释放资源(内核 -> 程序 -> 内存对象 -> 队列 -> 上下文)。
完整代码
1 |
|
openCL中的同步与事件
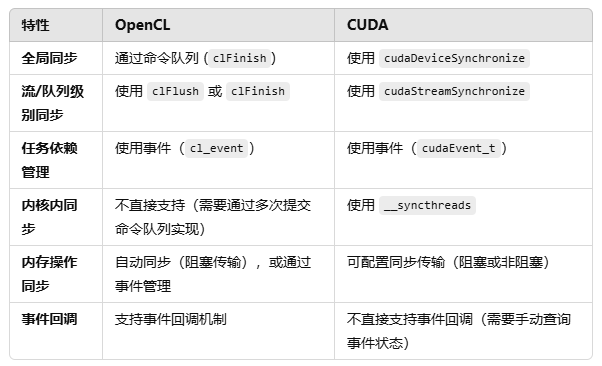
openCL中同步机制不如cuda,基本只有clFinish比较常用,而cuda中可以通过__syncxxxx实现不同粒度的同步。
OpenCL 的 clFinish 类似于 CUDA 的 cudaDeviceSynchronize,但作用范围仅限于指定的命令队列。clFlush 确保所有提交到队列中的命令开始执行,但并不等待完成,CUDA 的 cudaStreamSynchronize 类似于 clFlush,但 cudaStreamSynchronize 会等待指定流中的所有任务完成。OpenCL 不支持类似 CUDA __syncthreads 的内核内同步指令。如果需要同步,可以通过分阶段提交不同的命令到队列,并在每阶段使用 clFinish 或事件同步。
OpenCL中若要实现更细粒度的同步,通常需要借助事件,事件是 OpenCL 中用于管理异步任务的核心机制。
1.创建事件
在提交命令(如内核执行、内存传输等)时,可以指定一个事件对象,用于追踪该命令的状态。
1 | cl_event event; |
此时,event 记录了该命令的执行状态,可以用于后续同步。
2.等待事件
使用 clWaitForEvents 等待一个或多个事件完成。
函数原型:
1 | cl_int clWaitForEvents(cl_uint num_events, const cl_event *event_list); |
示例代码:
1 | clWaitForEvents(1, &event); // 等待单个事件完成 |
CUDA 的事件对象 cudaEvent_t 可以通过 cudaEventSynchronize 等待完成。
3.查询事件状态
使用 clGetEventInfo 查询事件的当前状态,例如是否完成。OpenCL 提供更丰富的状态查询功能,而 CUDA 的事件更多用于同步,不直接支持类似的状态查询。
函数原型:
1 | cl_int clGetEventInfo( |
参数说明:
param_name:指定要查询的信息类型。常用值:
CL_EVENT_COMMAND_QUEUE:返回事件关联的命令队列(类型为cl_command_queue)。CL_EVENT_COMMAND_TYPE:返回事件关联的命令类型(类型为cl_command_type,如CL_COMMAND_NDRANGE_KERNEL表示内核执行)。CL_EVENT_COMMAND_EXECUTION_STATUS:返回命令的执行状态(类型为cl_int,常见状态如下)。
CL_QUEUED:命令在队列中排队。CL_SUBMITTED:命令已提交到设备。CL_RUNNING:命令正在执行。CL_COMPLETE:命令执行完成。
CL_EVENT_REFERENCE_COUNT:返回事件对象的引用计数。
param_value_size:指定返回值缓冲区的大小(以字节为单位)。确保分配的缓冲区足够大以容纳返回值。param_value:指向存储返回值的缓冲区。函数会将查询结果写入这个缓冲区。param_value_size_ret:存储实际写入param_value的数据大小。如果不需要,可以设置为NULL。
示例代码:
查询事件状态:
1 | cl_event event; // 在内核执行或数据传输时生成的事件 |
查询事件的命令类型
1 | cl_command_type command_type; |
4.事件回调
OpenCL 支持为事件注册回调函数,在事件状态改变时(如内核执行完成、内存传输完成等)触发。
函数原型:
1 | cl_int clSetEventCallback( |
参数解释:
command_exec_callback_type:指定事件回调的类型。常用的状态值如下:CL_COMPLETE:表示当事件的执行状态变为CL_COMPLETE(完成)时触发回调。CL_SUBMITTED:表示当事件的执行状态变为CL_SUBMITTED(已提交)时触发回调。CL_RUNNING:表示当事件的执行状态变为CL_RUNNING(正在执行)时触发回调。CL_QUEUED:表示当事件的执行状态变为CL_QUEUED(已排队)时触发回调。
pfn_notify:回调函数的指针,函数将在事件状态变化时被调用。
回调函数签名:
1
void event_callback(cl_event event, cl_int event_command_exec_status, void *user_data);
event:事件对象本身,表示触发回调的事件。event_command_exec_status:事件的执行状态(例如CL_COMPLETE,CL_RUNNING等)。user_data:指向用户数据的指针,传递给回调函数,用于存储任何自定义信息。
user_data:可以传递给回调函数的用户自定义数据。例如,可以使用此参数传递上下文信息或其他有用的对象。
示例代码:
1 | // 回调函数:当事件完成时调用 |
参考资料
[1]. OpenCL 学习
[2]. 【高性能计算】opencl语法及相关概念(一):工作流程,实例
[3].以向量加法来学习opencl