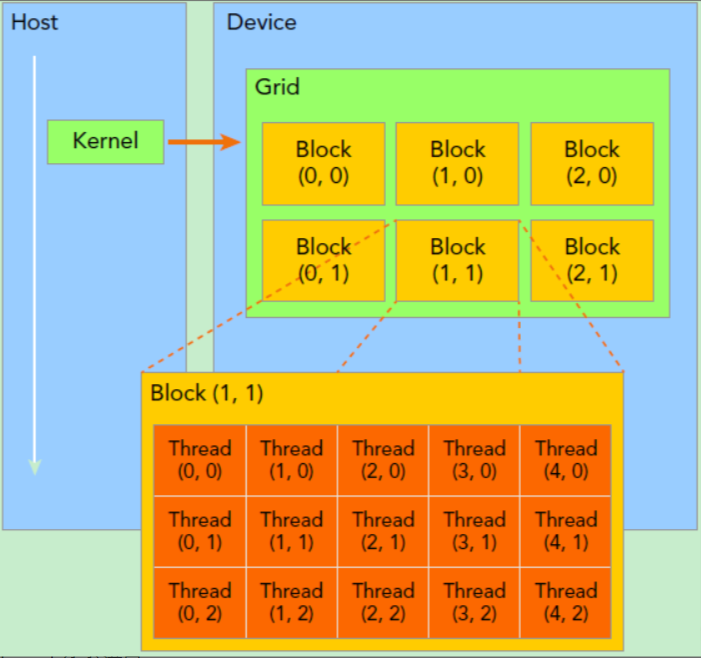
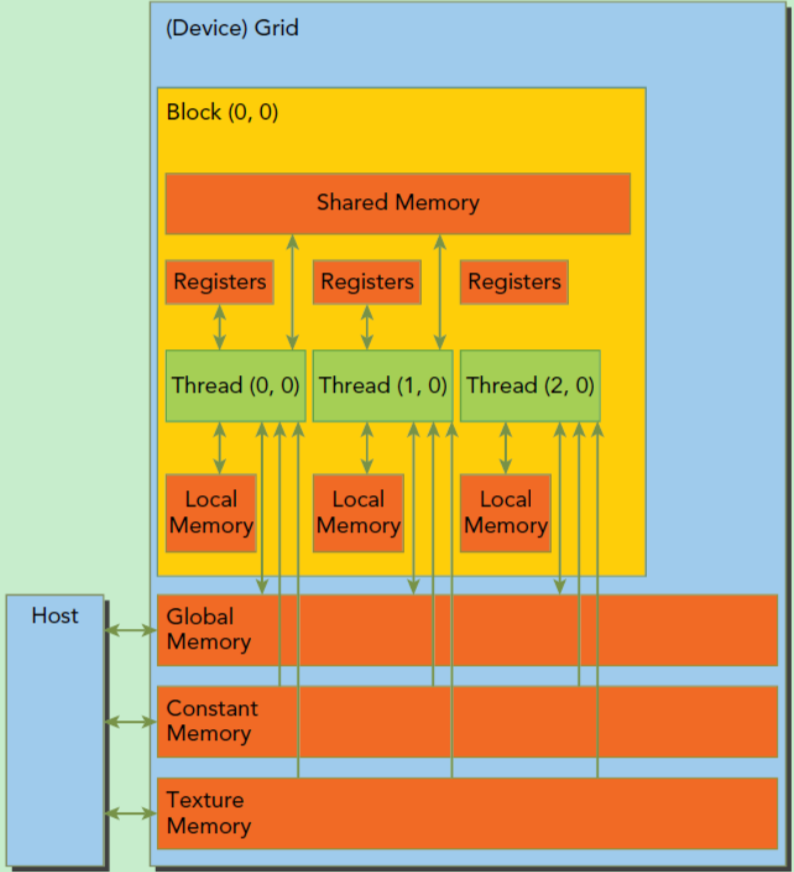
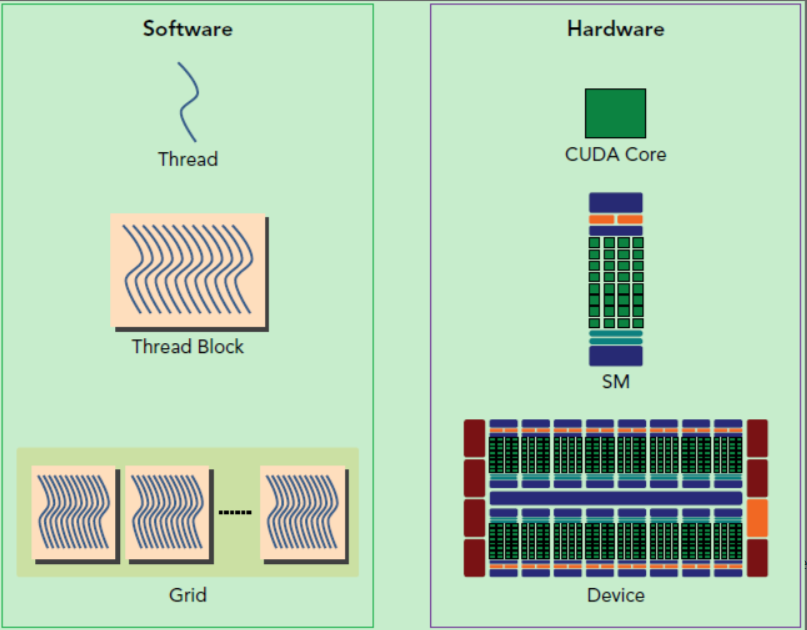
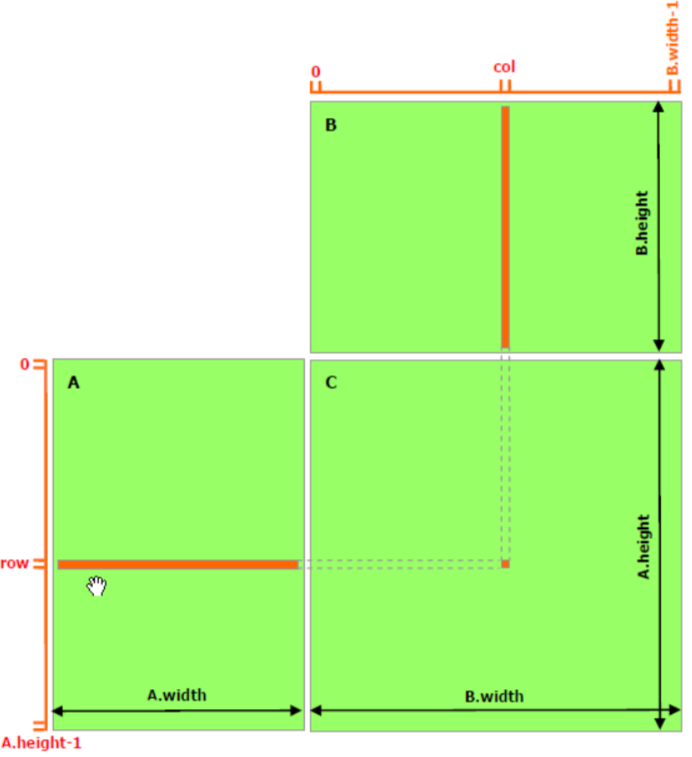
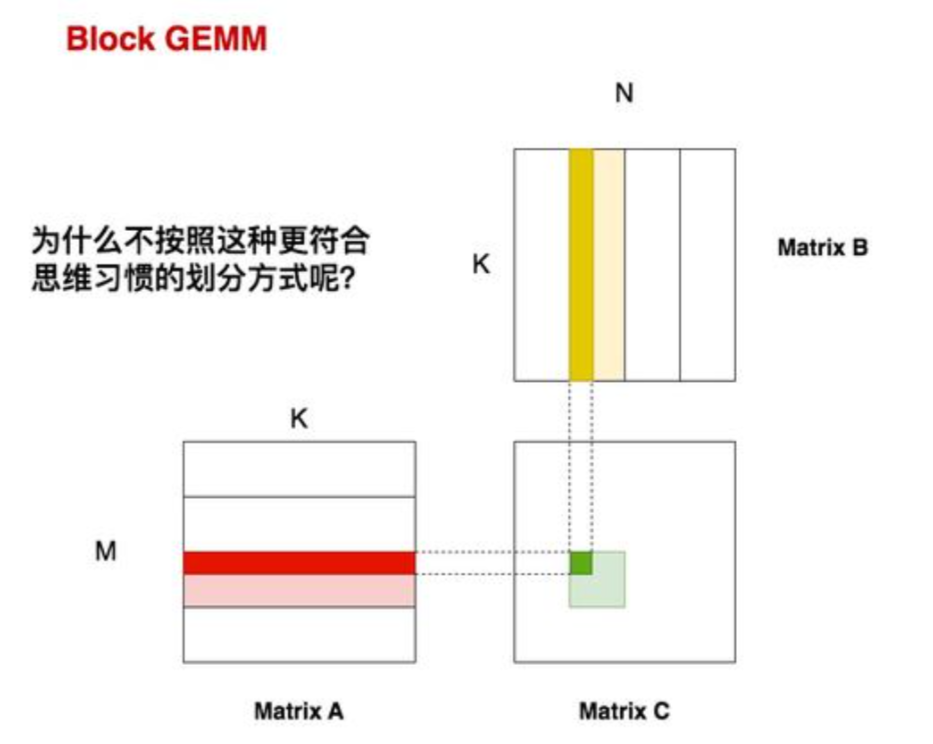
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
| #include <stdio.h>
#include <stdlib.h>
#include <float.h>
#include <cuda_runtime.h>
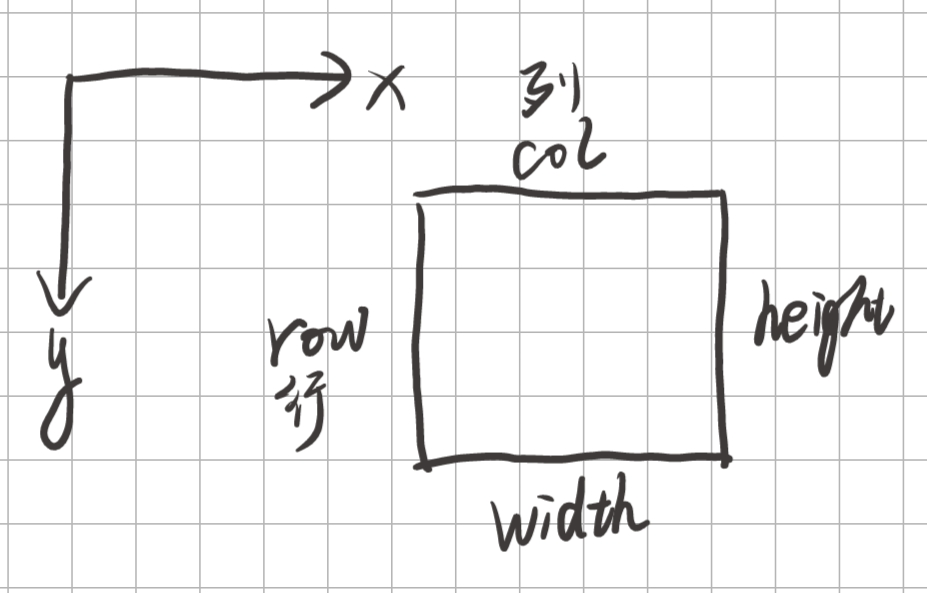
#define OFFSET(row, col, ld) ((row) * (ld) + (col))
void cpuSgemm(float *a, float *b, float *c, const int M, const int N, const int K);
__global__ void naiveSgemm(
float * __restrict__ a, float * __restrict__ b, float * __restrict__ c,
const int M, const int N, const int K);
float testError(void);
float testPerformance(
void (*gpuSgemm) (float *, float *, float *, const int, const int, const int),
dim3 gridDim, dim3 blockDim, const int M, const int N, const int K, const int repeat);
int main(void)
{
float max_error = testError();
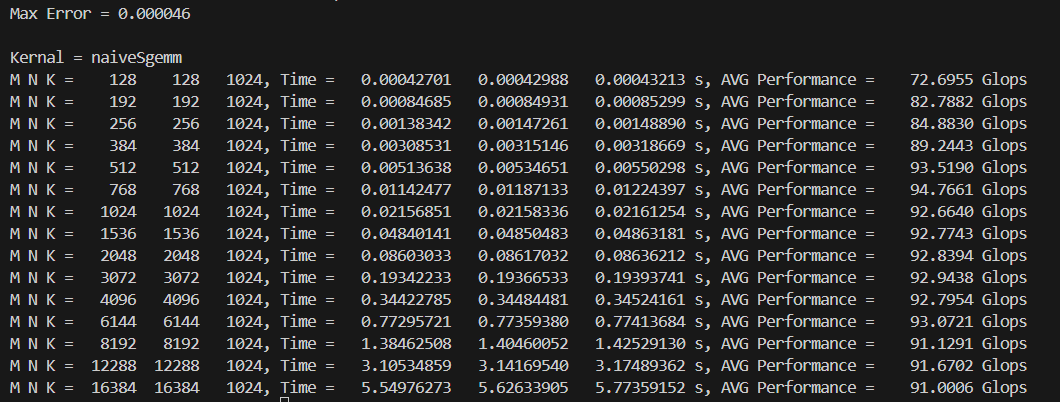
printf("Max Error = %f\n", max_error);
printf("\nKernal = naiveSgemm\n");
const int TESTNUM = 15;
const int M_list[TESTNUM] = {128, 192, 256, 384, 512, 768, 1024, 1536, 2048, 3072, 4096, 6144, 8192, 12288, 16384};
const int N_list[TESTNUM] = {128, 192, 256, 384, 512, 768, 1024, 1536, 2048, 3072, 4096, 6144, 8192, 12288, 16384};
const int K_list[TESTNUM] = {1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024, 1024};
const int outer_repeat = 10, inner_repeat = 1;
const int BM = 32, BN = 32;
void (*gpuSgemm) (float *, float *, float *, const int, const int, const int) = naiveSgemm;
for(int i = 0; i < TESTNUM; ++i)
{
const int M = M_list[i], N = N_list[i], K = K_list[i];
dim3 blockDim(BN, BM);
dim3 gridDim((N + BN - 1) / BN, (M + BM - 1) / BM);
double max_sec = 0.0;
double min_sec = DBL_MAX;
double total_sec = 0.0;
for(int j = 0; j < outer_repeat; ++j)
{
double this_sec = testPerformance(gpuSgemm, gridDim, blockDim, M, N, K, inner_repeat);
max_sec = max(max_sec, this_sec);
min_sec = min(min_sec, this_sec);
total_sec += this_sec;
}
double avg_sec = total_sec / outer_repeat / inner_repeat;
double avg_Gflops = ((double)M) * N * K * 2.0 / 1024.0 / 1024.0 / 1024.0 / avg_sec;
printf("M N K = %6d %6d %6d, Time = %12.8lf %12.8lf %12.8lf s, AVG Performance = %10.4lf Glops\n", M, N, K, min_sec, avg_sec, max_sec, avg_Gflops);
}
return 0;
}
void cpuSgemm(float *a, float *b, float *c, const int M, const int N, const int K)
{
for(int i = 0; i < M; ++i)
{
for(int j = 0; j < N; ++j)
{
float psum = 0.0;
for(int k = 0; k < K; ++k) psum += a[OFFSET(i, k, K)] * b[OFFSET(k, j, N)];
c[OFFSET(i, j, N)] = psum;
}
}
}
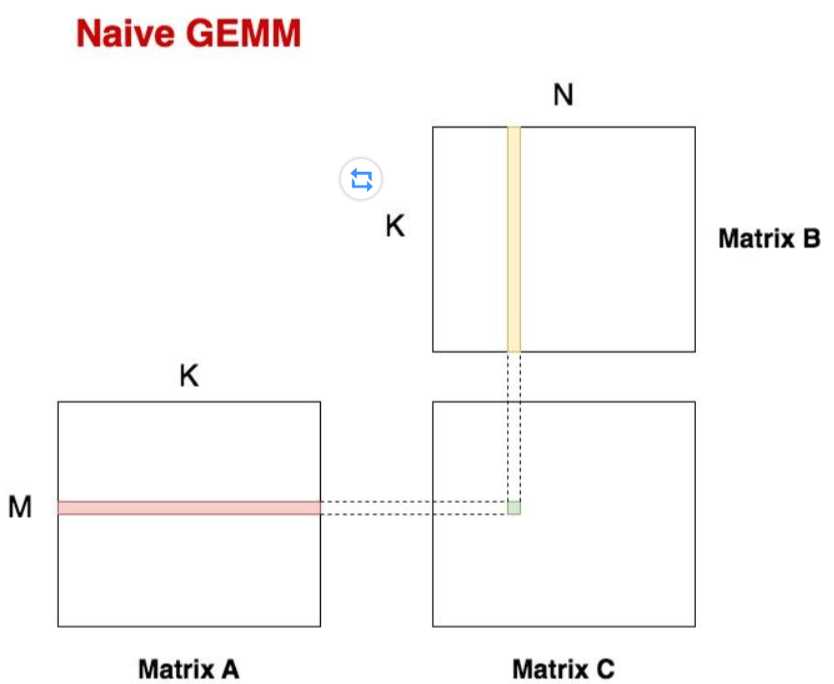
__global__ void naiveSgemm(
float * __restrict__ a, float * __restrict__ b, float * __restrict__ c,
const int M, const int N, const int K){
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
if(i < M && j < N)
{
float psum = 0.0;
#pragma unroll
for(int k = 0; k < K; ++k) psum += a[OFFSET(i, k, K)] * b[OFFSET(k, j, N)];
c[OFFSET(i, j, N)] = psum;
}
}
float testError(void)
{
const int BM = 32, BN = 32;
const int M = 512, N = 512, K = 512;
dim3 blockDim(BN, BM);
dim3 gridDim((N + BN - 1) / BN, (M + BM - 1) / BM);
size_t size_a = M * K * sizeof(float);
size_t size_b = K * N * sizeof(float);
size_t size_c = M * N * sizeof(float);
float *h_a, *h_b, *h_c, *d_a, *d_b, *d_c, *h_d_c;
h_a = (float *)malloc(size_a);
h_b = (float *)malloc(size_b);
h_c = (float *)malloc(size_c);
cudaMalloc(&d_a, size_a);
cudaMalloc(&d_b, size_b);
cudaMalloc(&d_c, size_c);
h_d_c = (float *)malloc(size_c);
srand(time(0));
for(int i = 0; i < M * K; ++i) h_a[i] = rand() / float(RAND_MAX);
for(int i = 0; i < K * N; ++i) h_b[i] = rand() / float(RAND_MAX);
cpuSgemm(h_a, h_b, h_c, M, N, K);
cudaMemcpy(d_a, h_a, size_a, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size_b, cudaMemcpyHostToDevice);
naiveSgemm<<<gridDim, blockDim>>>(d_a, d_b, d_c, M, N, K);
cudaMemcpy(h_d_c, d_c, size_c, cudaMemcpyDeviceToHost);
float max_error = 0.0;
for(int i = 0; i < M * N; ++i)
{
float this_error = fabs(h_d_c[i] - h_c[i]);
if(max_error != max_error || this_error != this_error) max_error = -NAN;
else max_error = max(max_error, this_error);
}
free(h_a);
free(h_b);
free(h_c);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
free(h_d_c);
return max_error;
}
float testPerformance(
void (*gpuSgemm) (float *, float *, float *, const int, const int, const int),
dim3 gridDim, dim3 blockDim, const int M, const int N, const int K, const int repeat){
size_t size_a = M * K * sizeof(float);
size_t size_b = K * N * sizeof(float);
size_t size_c = M * N * sizeof(float);
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, size_a);
cudaMalloc(&d_b, size_b);
cudaMalloc(&d_c, size_c);
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start);
for(int i = 0; i < repeat; ++i) gpuSgemm<<<gridDim, blockDim>>>(d_a, d_b, d_c, M, N, K);
cudaEventRecord(end);
cudaEventSynchronize(end);
float msec, sec;
cudaEventElapsedTime(&msec, start, end);
sec = msec / 1000.0 / repeat;
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return sec;
}
|