CUDA高级编程
CUDA 高级编程
CUDA中的同步与通信机制
核函数之间(核函数的异步执行与阻塞同步)
cudaDeviceSynchronize()cudaDeviceSynchronize()的主要功能是 阻塞 CPU 线程,直到 GPU 上的所有任务都完成。除此之外,还能帮助检测错误。在cuda 11.6中device端的cudaDeviceSynchronize()已经被弃置了,主机端仍支持。cudaStreamSynchronize()与
cudaDeviceSynchronize()类型,只不过是等待特定的流中所有任务完成,而不是设备上的所有任务。cudaSetDeviceFlags ()用于设置CPU阻塞后的等待方式,默认模式(
cudaDeviceScheduleAuto)是轮询(polling)模式,cudaDeviceScheduleBlockingSync模式是让主机进入休眠状态,不会轮询GPU任务完成情况,只有当GPU完成任务发出信号时,主机线程才会被唤醒继续执行。1
__host__ cudaError_t cudaSetDeviceFlags ( unsigned int flags )
1
cudaSetDeviceFlags(cudaDeviceScheduleBlockingSync);
cudaLaunchKernel()用于 手动启动核函数 的 API,它允许以更加灵活的方式配置和启动核函数。
1
2
3
4
5
6
7
8cudaError_t cudaLaunchKernel(
const void* func, // 核函数的指针
dim3 gridDim, // 网格的维度 (网格大小)
dim3 blockDim, // 每个线程块的维度 (块大小)
void** args, // 核函数参数的数组
size_t sharedMem, // 每个块的动态共享内存大小(字节)
cudaStream_t stream // 要在其上执行核函数的流
);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41//示例代码
dim3 blockIdx, threadIdx, blockDim, gridDim;
__global__ void myKernel(int a, int b, int* c)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx == 0) *c = a + b;
}
int main()
{
int a = 5, b = 10;
int h_c;
int* d_c;
cudaMalloc(&d_c, sizeof(int));
// 准备参数
void* args[] = { &a, &b, &d_c };
// 使用 cudaLaunchKernel 启动核函数
dim3 grid(1);
dim3 block(1);
cudaLaunchKernel((void*)myKernel, grid, block, args, 0, 0);
// 同步并检查结果
cudaMemcpy(&h_c, d_c, sizeof(int), cudaMemcpyDeviceToHost);
printf("Result: %d\n", h_c);
cudaFree(d_c);
return 0;
}
块内所有线程间的同步
__syncthreads()
在 CUDA 编程中,__syncthreads() 是一个非常重要的内建函数,用于在一个线程块内同步所有线程。它确保在调用点之前,线程块内的所有线程都已经执行到 __syncthreads() 这一行代码,并且所有线程的内存操作(读写)都已经完成。这对于确保线程块内共享内存中的数据一致性至关重要。
1 |
|


注意死锁问题! __syncthreads()必须要能被块内所有线程均可以执行!因此,不要将其放置在IF语句中,以免导致某些线程永远无法到达__syncthreads()。
1 | //错误写法 |
1 | //正确写法 |
例子: 跨线程块的全局队列的实现(Global work queue)
- 背景:同一个核函数的多个线程块共同处理一个大任务
- 思路:可以将大任务划分成小任务队列,然后由各个线程块处理这些小任务。这里有一个全局任务队列的实现问题。
1 | class WorkQueue { |
__syncthreads()的变种
__syncthreads_or()针对到达同步点的线程,进行
predicate评估并做逻辑判定!如果块内任何一个线程的谓词predicate为非零(即为真),则返回非零值;否则,返回零。(or)1
2int __syncthreads_or(int predicate);
//谓词predicate是一个条件表达式,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23__global__ void checkConditionKernel(int *data, int *result, int threshold) {
// 获取线程索引
int idx = threadIdx.x;
// 检查每个线程的数据是否大于阈值
int predicate = (data[idx] > threshold);
// 使用 __syncthreads_or() 进行全局检查,如果任何一个线程的条件为真,则返回非零值
int anyThreadSatisfied = __syncthreads_or(predicate);
// 仅当有任何一个线程满足条件时,才执行某个操作
if (anyThreadSatisfied) {
// 如果有任意一个线程满足条件,我们将标志位设置为1
if (idx == 0) {
*result = 1;
}
} else {
// 否则,将标志位设置为0
if (idx == 0) {
*result = 0;
}
}
}__syncthreads_and()and,与__syncthreads_or()类似1
int result = __syncthreads_or(predicate);
__syncthreads_count()返回满足谓词
predicate的线程数。1
int count = __syncthreads_count(predicate);
例子:Last-block guard(确定最后一个线程块!)
场景:考虑线程网格(核函数)正在进行一些任务,例如并行归约, [两项任务!] 。
最初,每个块可以独立完成工作,产生部分结果。 然后,这些部分结果需要被组合和合并在一起。
- 思路1:使用两个核函数,一个用于部分计算,另一个用于合并。
- 思路2:用一个核函数,将合并功能由一个线程块完成。这需要通过定义为lastBlock的功能来实现。即:判定是否是最后的一个线程块已经执行完成!
- 思路3:专门化线程束技术
伪代码:
1 | __device__ void computePartial(T* out) { ... } //计算部分结果 |
lastBlock的第一种实现:
1 | __device__ int counter =0; //counter是一个全局内存中的全局共享变量,初始化为0. |
__threadfence(): 确保了调用它的线程在此之前对 全局内存(global memory)、共享内存(shared memory)、局部内存(local memory) 所做的所有写入操作对设备内其他线程(无论是同一线程块内还是不同线程块内)都是可见的。
lastBlock的第二种实现:
1 | __device__ int counter =0; //counter是一个全局内存中的全局共享变量,初始化为0. |
两种实现的区别:
第一种需要等待块内所有线程完成同步之后,才能确定当前块是否为“最后线程块”!
第二种只需要块内0号线程完成之后即可确定是否为“最后线程块”
Block之间的同步
线程块之间的同步是有必要的。前提是这些线程块均被发射(资源够用)
锁+原子操作
CUDA 基于锁的线程块同步的基本思想是使用一个全局变量来计算到达同步点的线程块的数量。
每个线程块的0号线程负责同步机制,利用原子操作维护全局锁变量,并判定是否到同步点,利用__syncthreads进一步同步块内其他线程。
调用__gpu_sync()实现核函数内的所有线程块同步。
1 | __device__ goalVal = N; // N为核函数的线程块数量;常量 |
无锁
完全避免使用原子操作的无锁同步方法。
基本思想是为每个线程块分配一个同步变量,形成一个数组Arrayin ,这样每个块就可以独立地记录其同步状态,而不必争用单个全局互斥锁变量。 线程块 1被用作控制用(也可以用其他块)。(将块间同步转为块内线程同步)
无锁同步方法使用两个全局数组Arrayin 和 Arrayout来协调来自不同块的同步请求。在这两个数组中,每个元素都映射到核函数中的一个线程块,即,将元素i 映射到线程块 i。然后利用块内同步来支持块间同步。
1 | __device__ void __gpu_sync(int goalVal, volatile int *Arrayin, volatile int *Arrayout) { |
每个线程块i的0号线程会将Arrayin[i]设置为goalVal,而线程块1的每个线程i负责检查Arrayin[i]是否为goalVal,如果是,则将Arrayout[i]设置为goalVal。
Arrayin数组的作用是告诉线程块1,对应的线程是否完成了初识化,所以,这个数组是由每个线程块的0号线程写,被线程块1中的线程读。Arrayout数组的作用是告诉对应的线程块,目前所有的线程块都完成了初识化,可以继续后续操作了,所以,是由线程块1中的线程在确认所有线程块完成初识化后写,由每个线程块的0号线程读。(线程块1被用作控制块,也可用其他块)
内存围栏(memory fence)
存在存储一致性(内存一致性)问题,类似于操作系统第二章的一致性和缓存一致性的问题。弱顺序一致性(允许编译器重排)、写入延迟、缓存一致性。
内存围栏只会影响一个线程(自己线程)中内存操作的顺序,(并最终反映到内存存储中!)。他并不能像__syncthreads()那样保证这些内存操作对于同block中的其他线程可见。
对于nvcc编译器来说,编译器是可以自由地优化全局内存和共享内存的读写顺序。例如,这种优化可以是通过寄存器或L1缓存实现。但是,这种优化,必须要服从由内存围栏函数所定义出的内存顺序语义,还必须要服从同步函数所限制的内存可见性语义。(内存围栏和同步函数可以在一定程度上限制编译器优化,以防止出现一些内存一致性)
1 | _device__ volatile int X = 1, Y = 2; |
根据初始化值,读,写操作的顺序不同,有可能的结果:
A=1,B=2(读A,读B,…)
A=10,B=2(写X,读A,读B,…)
A=10,B=20(写X,写Y,读A,读B)
由此看见需要内存围栏函数,内存围栏函数可以用来对内存访问进行一些排序。
内存围栏:用来保证线程间数据通信的可靠性。只保证执行memory fence函数的线程生产的数据能够安全地被其他线程消费。
1 | void __threadfence(); |
1 | void __threadfence_block(); |
1 | void __threadfence_system(); |
与同步函数不同, threadfence不是保证所有线程都完成同一操作,而只保证正在进行fence的线程本身的I/O操作能够安全可见所有线程,fence不要求线程运行到同一位置。
内存围栏例子(一个Grid(多个块)归约求和!):
1 | __device__ unsigned int count = 0; |
线程束内以及线程束间
- 线程束是SM的基本执行和调度单元。
- 一个线程束包含32个并行线程,这32个线程执行于SIMT模式。所有线程执行同一条指令,并且每个线程会使用各自的data执行指令。
- 一个线程束中的线程必然在同一个block中,如果block所含线程数目不是线程束大小的整数倍,那么多出的那些线程所在的线程束中,会剩余一些空闲的线程。
- 线程束可以实现寄存器级的数据交换(shuffle指令)
- 线程束可以实现细粒度的同步与通信。
对共享变量的互斥访问(原子操作)
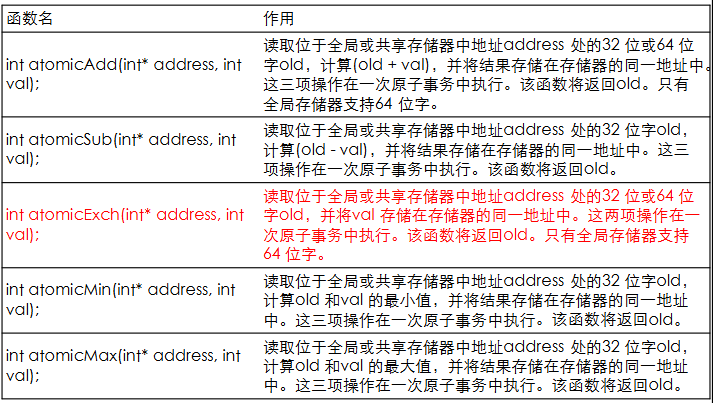
原子操作只适用有符号和无符号整数或浮点数,以及新浮点数类型等(除了AtomicExch)。
- 新浮点数:
__half,bfloat16
- 新浮点数:
原子加法
atomicAdd1
int atomicAdd(int* address, int val);
读取位于全局或共享存储器中地址
address处的32 位或64 位字old,计算($old + val$),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。只有全局存储器支持64 位字。其他原子操作
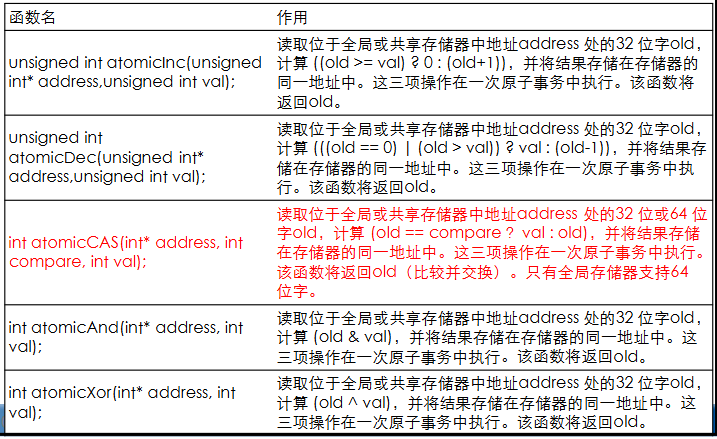
大多数原子操作都是基于
atomicCAS实现的1
int atomicCAS(int* address, int compare, int val);
读取位于全局或共享存储器中地址address 处的32 位或64 位字old,计算 (old == compare ?val : old),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old(比较并交换)。只有全局存储器支持64位字。
1
2
3
4
5
6
7
8
9
10
11
12__device__ double atomicAdd(double* address, double val)
{
unsigned long long int* address_as_ull = (unsigned long long int*)address;
unsigned long long int old = *address_as_ull;
unsigned long long int assumed;
do{
assumed = old;
old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val + __longlong_as_double(assumed)));
}while(assumed != old);
return __longlong_as_double(old);
}
例子:原子操作的必要性
1 | __global__ void increment_naive(int *g) |
不能离开线程组织配置看核函数!
取决于ARRAY_SIZE的值!如果NUM_THREADS > ARRAY_SIZE,则会出现写冲突,必须原子操作。
原子操作举例:层次化原子操作
1 | __global__ void sum(int *input, int *result) |
矩阵乘法例子
(稠密的)矩阵乘法
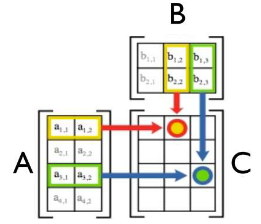
$c_{i,j} = \sum_{k=0}^{l-1}a_{i,k}*b_{k,j} $
1 | void matriMult(int a[N][N], int b[N][N], int c[N][N], int width) |
方法1:朴素方法
以目标结果矩阵的每个元素的计算为基础:
- 将目标结果矩阵看做1D数组,逐一计算每个元素,每个线程负责一个元素。无考虑线程组织结构。
- 源矩阵的元素如何访问?将2D矩阵展开成1D数组,然后逐个元素访问
- 线程如何组织?假设为1D Grid ,1D Block
- 目标矩阵压缩为1D
- 不同组织结构的线程均转变为1D
- 每个线程负责一个目标元素,即
C[i][j]
局限性:
- 没有充分发挥CUDA的线程组织结构
- 没有利用共享内存
方法2:GMM-thread-no-shared memory(线程级-无共享内存)
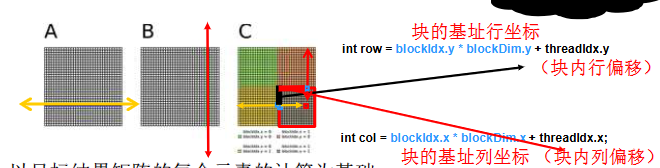
1 | int row = blockIdx.y * blockDim.y + threadIdx.y; |
以目标结果矩阵的每个元素的计算为基础:
- 考虑线程块结构,但没有使用共享内存!
- 源矩阵的元素如何访问?依然按1D方式访问源矩阵A和B。(按行/按列)
- 线程如何组织?X Grid,2D Block
- 目标矩阵的元素如何访问?按2D方式访问,保留块的2D索引,块内2D线程压平为1D形式来处理源矩阵1D数据,增加了线程数量!依然每个线程负责一个目标元素!
1 | typedef struct { |
1 | // CUDA核函数:矩阵乘法 |
1 | void MatMul(const Matrix A, const Matrix B, Matrix C) { |
方法3: GMM-block-stride-with-shared memory(块级-步幅-带共享内存)
条带式划分矩阵,添加一个步幅(stride)参数。(可以简单理解为stride=width)
方法2没有充分利用共享内存,计算访问比太低。(每个线程都直接从全局内存中读取矩阵元素,全局内存访问的延迟较大,数据访问的开销较大,计算与访问的比率偏低)
1 | // 矩阵依然采用行优先存储: |
每个线程块负责计算目标矩阵C的子矩阵Csub,而线程块中的线程负责计算子矩阵Csub中的元素。充分利用已经读取的矩阵A/B元素。
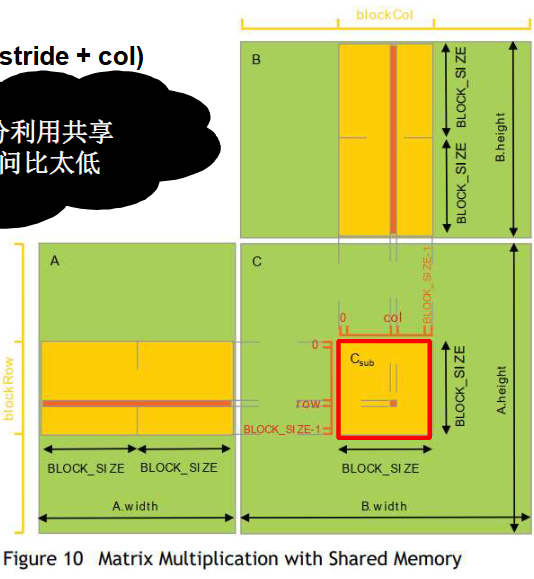
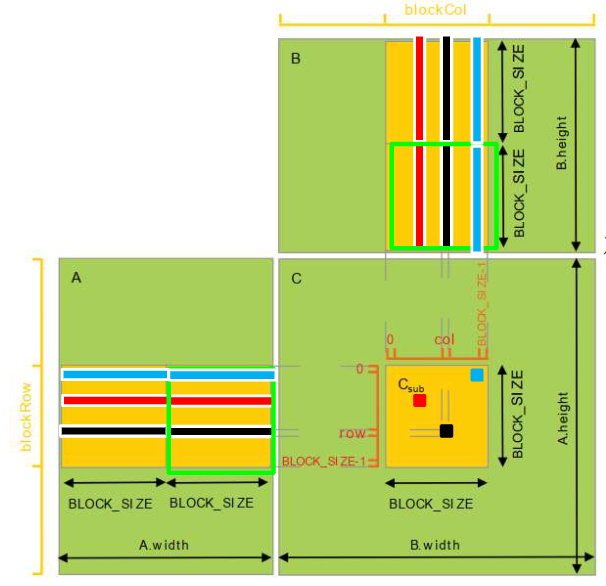
1 | __device__ float GetElement(const Matrix A, int row, int col) { |
1 |
|
CUDA计算能力及GPU架构特性
计算能力描述了硬件的功能,并反映了设备支持的指令集以及其他规范,例如每个块的最大线程数和每个多处理器的寄存器数。较高的计算能力版本是较低(即较早)版本的超集,因此它们向后兼容。
CUDA编译链及兼容性问题
CUDA编译链大致分为以下几个步骤:
- 预处理
- 主机代码和设备代码分离
- 设备代码编译:编译为PTX,是一种虚拟架构的中间表示形式,或者直接编译为目标 GPU 架构的二进制代码。
- 主机代码编译
- 链接
nvcc
nvcc 是 CUDA 的编译器驱动程序,类似于 gcc 或 clang。具体来说,nvcc 将主机代码发送到标准 C++ 编译器处理,将设备代码交给 CUDA 编译器生成 PTX 或二进制代码,然后将它们合并起来形成最终的可执行文件。
虚架构 (Virtual Architecture)
虚架构是指 PTX 中间表示,它是设备代码的汇编语言级别的中间表示。PTX 是 CUDA 的一种抽象层,它与具体的硬件无关,这样可以实现代码的跨架构兼容性。代码首先被编译为 PTX,这样可以针对未来的新硬件架构进行重新编译和优化,而无需修改源代码。
实架构 (Real Architecture)
实架构是指目标 GPU 的具体硬件架构。每代 NVIDIA GPU 都有其独特的架构,例如 Fermi、Kepler、Pascal、Volta、Ampere 等。实架构通常用 compute_xx 和 sm_xx 来表示,compute_xx 代表虚拟架构(表示支持的功能集),而 sm_xx 则代表实际的硬件架构(表示具体的硬件实现)。
Virtual Architecture应该尽可能的低,以最大化你的CUDA程序可以运行的环境。Real Architecture尽可能的高,尽量依据驱动/运行时库和GPU卡的知识指定。
离线编译
离线编译是指在开发时,直接将 CUDA 代码编译成适合特定 GPU 架构的二进制代码。在这种模式下,所有的编译工作都在编译时完成,运行时不会再进行编译。这种方式灵活性较低,离线编译生成的二进制代码只能在特定的 GPU 上运行。如果更换了 GPU,就需要重新编译。
1 | nvcc -arch=sm_70 your_program.cu -o your_program |
即时编译
即时编译指的是在程序运行时,对特定的 PTX 代码进行编译,使其适应当前的 GPU 架构。这种方式允许代码具有更高的灵活性,因为它在运行时根据具体的硬件情况生成二进制代码。
1 | nvcc -arch=compute_70 -code=compute_70,sm_70 your_program.cu -o your_program |
与Virtual 和 Real Architectures 相关的参数设置
--gpu-architecture arch (-arch)- 指定NVIDIA虚拟GPU架构的名称。这个参数必须是virtual architecture
(such as compute_50).
- 指定NVIDIA虚拟GPU架构的名称。这个参数必须是virtual architecture
--gpu-code code,... (-code)- 指定生成的机器指令符合的GPU架构的名称,可以是real architecture名称,也可以是virtual architecture名称。例如sm_50,或compute_50。
--generate-code specification (-gencode)这个参数提供了一种组合形式,—gpu-architecture=archXX —gpucode=codeXX,… 用来指定nvcc的代码编译。
1
-gencode arch=compute_35,code=sm_35
CUDA的执行调度模型
CUDA 的执行调度模型主要是指 GPU 如何安排线程并执行 CUDA 核函数(kernel)。这其中涉及到多个层次的调度机制,确保高效并行计算。
1 |
|
每个流多处理器核(SMM Core)中,有一些执行单元,Warp调度器,共享内存,L1缓存,取值/译码单元等。每个线程块分配到某一个流多处理器;分配的依据是各类资源的约束;
- 第 1 步:主机向设备发送执行命令
- 第 2 步:调度器将 Block 0 映射到 Core 0(保留 128 个线程的执行上下文和 520 字节的共享存储)
- 第 3 步:调度器继续将线程块映射到可用的执行上下文(展示交错映射)
GPGPU-Sim原理
GPGPU-Sim 是一个模拟通用图形处理单元(GPGPU)的工具,旨在为学术研究和架构探索提供平台,允许研究者模拟 GPU 程序的执行过程。它主要用于研究和开发 GPU 硬件架构和 GPU 应用程序优化技术。
GPGPU-Sim 模拟了 GPU 的硬件架构,包括多核架构(通常被称为 streaming multiprocessors,或 SM)、内存层次结构(共享内存、全局内存、寄存器文件等)、线程调度器、指令流等。
CUDA Driver
CUDA Driver 是 NVIDIA 提供的底层软件,负责管理 GPU 的资源并执行 CUDA 程序。它作为应用程序与 GPU 硬件之间的桥梁,提供了一套与操作系统交互的接口,使开发者能够在不同的硬件平台上运行 CUDA 程序。它有一个兄弟叫做CUDA Runtime。
CUDA API的三个层次:CUDA Driver API、CUDA Runtime API、CUDA Library API。
驱动程序API和运行时API非常相似,在大多数情况下可以互换或混合使用。两者之间有一些关键区别。驱动API提供了更精细的控制,特别是对上下文和模块的加载:
- 核函数启动的实现要复杂得多,因为执行配置和核函数参数必须用显式函数调用来指定。
- 在运行时API,所有核函数都会在初始化过程中自动加载,并且在程序运行过程中一直保持加载状态,而使用驱动API,可只保持当前需要加载的模块,甚至可以动态地重新加载模块。
- 上下文管理通过驱动API完成,在运行时API中没有暴露。
CUDA Driver API
CUDA Context
- 上下文管理通过驱动程序API完成,不会在运行时API中公开。
- 运行时API自行决定要为线程使用哪个上下文。如果通过驱动程序API使当前上下文成为调用线程的当前上下文,则运行时将使用该上下文,但是如果没有这样的上下文,它将使用“primary context” 。
- 根据需要创建primary context。每个设备每个进程一个primary context,对其进行引用计数,然后当不再有对它们的引用时将其销毁。
- 在一个进程中,运行时API的所有用户都将共享primary context。
如果是runtime api,则调用会隐式调用创建context的函数,如cudasetdevice,cudaDeviceSynchronize.
如果是driver api,则必须使用cuCtxCreate.