CUDA 编程基础
1. Hello world,Cuda in C
2. VectorAdd,Cuda的线程组织
3. CPU与GPU之间的数据传输
4. CUDA中的各级存储资源
5. CUDA的流与事件
第1部分cuda in c主要简单了解一下cuda的程序,比较重要的内容是核函数(声明、调用) 、主机与设备 、函数和变量类型修饰符 。
第2部分有两个方面,vectoradd 这部分能学到比较简单的并行计算的运用 ,线程组织这部分主要理解网格(grid)、线程块(block)、线程(thread) 这三级结构,能够计算线程唯一ID 。
第3部分主要讲数据传输 ,把数据从cpu端传输到gpu端、gpu端传输的cpu端。
第4部分主要讲存储资源 ,主要是是指寄存器 、全局内存 、共享内存 、常量内存 等之类的。
第5部分是流和事件 ,cuda操作会放到流中,然后进行执行,简单理解流就是个FIFO的队列 ,事件可以理解为断点,帮助cuda操作进行同步、测量 事件。
Hello world,Cuda in C 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <stdio.h> #include <cuda_runtime.h> __global__ void hello () printf ("Hello World, Cuda In C !\n" ); } int main () hello<<<1 , 4 >>>(); printf ("I am the CPU: Hello World!\n" ); cudaDeviceSynchronize (); return 0 ; }
头文件cuda_runtime.h:CUDA运行时库的头文件,提供CUDA 的核心功能,这里主要是函数cudaDeviceSynchronize()需要用到。
__global__:声明内核函数,由CPU调用,在GPU上执行。返回值必须是void。CUDA执行模型:线程(Thread)、线程块(Block)、网格(Grid)
cudaDeviceSynchronize()的作用:同步CPU和GPU。运行到这行代码时,程序会暂停,直到GPU完成所有工作。代码的输出应该是先1行CPU的输出,再4行GPU的输出。如果没有这行代码,程序的输出会有所不同,可能GPU还没来得及输出,程序就结束了,也可能CPU的输出在GPU输出之前、之间、之后。
主机-设备架构(Host-Device Architecture) 主机=CPU 设备=GPU
将输入数据从 CPU 内存复制到 GPU 内存
加载 GPU 程序并执行,将数据缓存到芯片上以提高性能
将结果从 GPU 内存复制到 CPU 内存
函数类型限定符
__global__
由主机 调用,在设备 上执行
任何对 __global__ 函数的调用都必须指定该调用的执行配置。执行配置定义将用于在该设备上执行函数的网格和块的维度,共享内存的大小,以及相关的流。
在函数名称和括号参数列表之间插入<<<Dg, Db, Ns, S >>>表达式来指定。
1 myKernel<<<dim3 (2 , 3 ), dim3 (16 , 16 ), 1024 >>>();
__device__
__host__
变量类型限定符
__device__
位于全局内存空间
从它创建开始,持续保持,与CUDA上下文的生命周期一样,
可以被GPU上的所有线程访问 ,在主机代码中不可见,但是可以通过一些库函数在Host端被访问 。(cudaGetSymbolAddress() /cudaGetSymbolSize()cudaMemcpyToSymbol()/cudaMemcpyFromSymbol())
__constant__
可以和__device__一起使用
位于常量内存空间
与CUDA上下文的生命周期一样,
可以被GPU上的所有线程访问 ,在主机代码中不可见,但是可以通过一些库函数在Host端被访问 。(cudaGetSymbolAddress() /cudaGetSymbolSize()cudaMemcpyToSymbol()/cudaMemcpyFromSymbol())
__shared__
可以和__device__一起使用
位于共享内存 空间,每个线程块有一个独立的共享内存空间
与线程块的生命周期一样
只能被线程块内的所有线程访问 不能有常量地址(地址在每个线程块启动时动态确定)
__managed__
可以和__device__一起使用
可以被设备端和主机端的代码访问,可以直接的被读或写;
与应用程序的生命周期一致;
被__managed__修饰的变量的地址不会是常量不变的;因此不能被const修饰
被__managed__修饰的变量不能是引用类型;
在设备代码中声明的自动变量,如果不带 __device__ 、 __shared__ 和__constant__ 限定符中的任何一个时,通常位于寄存器中。
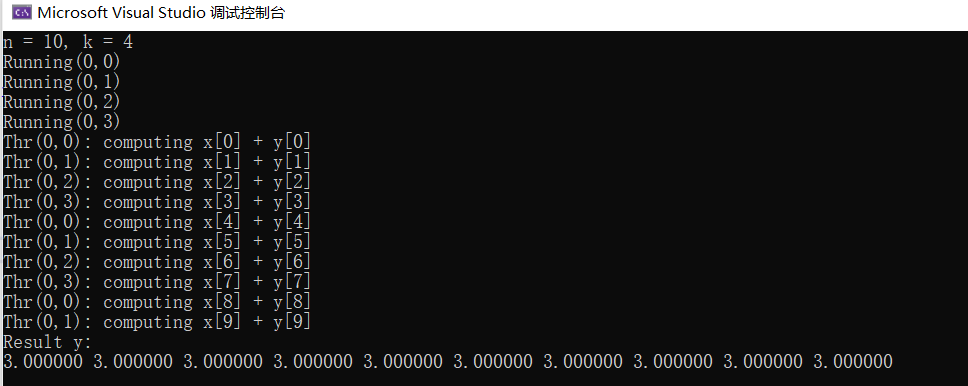
VectorAdd,Cuda的线程组织 VectorAdd add 1.0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <stdio.h> #include <cuda_runtime.h> __global__ void add (int n, double * x, double * y) printf ("Running(%d,%d)\n" , blockIdx.x, threadIdx.x); for (int i = 0 ; i < n; ++i) { y[i] = x[i] + y[i]; } } int main (int argc, char * argv[]) int n = atoi (argv[1 ]); double *x, *y; cudaMallocManaged (&x, n * sizeof (double )); cudaMallocManaged (&y, n * sizeof (double )); for (int i = 0 ; i < n; ++i) { x[i] = 1.0 ; y[i] = 2.0 ; } add << <1 , 1 >> > (n, x, y); cudaDeviceSynchronize (); printf ("Result y:\n" ); for (int i = 0 ; i < n; ++i) { printf ("%f " , y[i]); } printf ("\n" ); cudaFree (x); cudaFree (y); return 0 ; }
1 cudaMallocManaged (&x, n * sizeof (double ));
分配的内存是 托管内存 ,这块内存可以被 CPU 和 GPU 同时访问。CUDA 的托管内存管理机制会在需要的时候自动处理数据在 CPU 和 GPU 之间的传输。这简化了编程,因为你不需要手动进行数据拷贝。
这份代码没有对线程进行识别,相当于每个线程都把n个数字相加了,这不符合并行计算的初衷,并且只分配了1个线程。
gridDim.x:网格中沿 x 轴的线程块数量。
blockDim.x:线程块中沿 x 轴的线程数量。
blockIdx.x:当前线程块在其所在的网格(Grid)中的一维索引。范围是 0 到 gridDim.x - 1。
threadIdx.x:当前线程在其所在的线程块(Block)中的一维索引。范围是 0 到 blockDim.x - 1。
计算线程的全局索引:
1 int globalIdx = blockIdx.x * blockDim.x + threadIdx.x;
add 2.0 分配k个线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <stdio.h> #include <cuda_runtime.h> __global__ void add (int n, double * x, double * y) int index = threadIdx.x; int stride = blockDim.x; printf ("Running(%d,%d)\n" , blockIdx.x, threadIdx.x); for (int i = index; i < n; i += stride) { printf ("Thr(%d,%d): computing x[%d] + y[%d]\n" , blockIdx.x, threadIdx.x, i, i); y[i] = x[i] + y[i]; } } int main (int argc, char * argv[]) int n = atoi (argv[1 ]); int k = atoi (argv[2 ]); double *x, *y; cudaMallocManaged (&x, n * sizeof (double )); cudaMallocManaged (&y, n * sizeof (double )); for (int i = 0 ; i < n; ++i) { x[i] = 1.0 ; y[i] = 2.0 ; } add << <1 , k >> > (n, x, y); cudaDeviceSynchronize (); printf ("Result y:\n" ); for (int i = 0 ; i < n; ++i) { printf ("%f " , y[i]); } printf ("\n" ); cudaFree (x); cudaFree (y); return 0 ; }
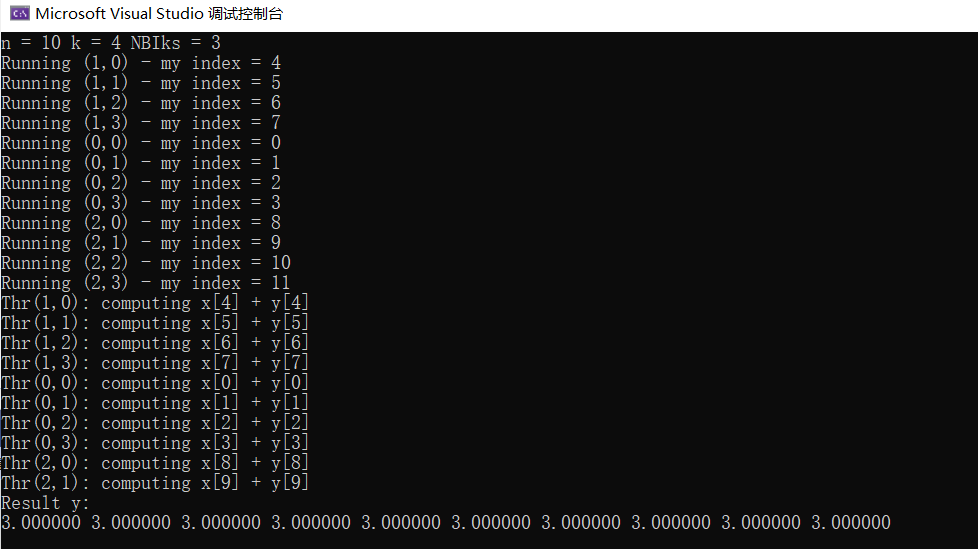
add 3.0 分配NBIks个线程块,每个线程块包含k个线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <stdio.h> #include <cstdlib> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim; #endif __global__ void add (int n, double * x, double * y) int index = blockIdx.x * blockDim.x + threadIdx.x; printf ("Running (%d,%d) - my index = %d\n" , blockIdx.x, threadIdx.x, index); if (index < n) { printf ("Thr(%d,%d): computing x[%d] + y[%d]\n" , blockIdx.x, threadIdx.x, index, index); y[index] = x[index] + y[index]; } } int main (int argc, char * argv[]) int n = atoi (argv[1 ]); int k = atoi (argv[2 ]); int NBIks = (n + k - 1 ) / k; printf ("n = %d k = %d NBIks = %d\n" , n, k, NBIks); double * x, * y; cudaMallocManaged (&x, n * sizeof (double )); cudaMallocManaged (&y, n * sizeof (double )); for (int i = 0 ; i < n; ++i) { x[i] = 1.0 ; y[i] = 2.0 ; } add << <NBIks, k >> > (n, x, y); cudaDeviceSynchronize (); printf ("Result y:\n" ); for (int i = 0 ; i < n; ++i) { printf ("%f " , y[i]); } printf ("\n" ); cudaFree (x); cudaFree (y); return 0 ; }
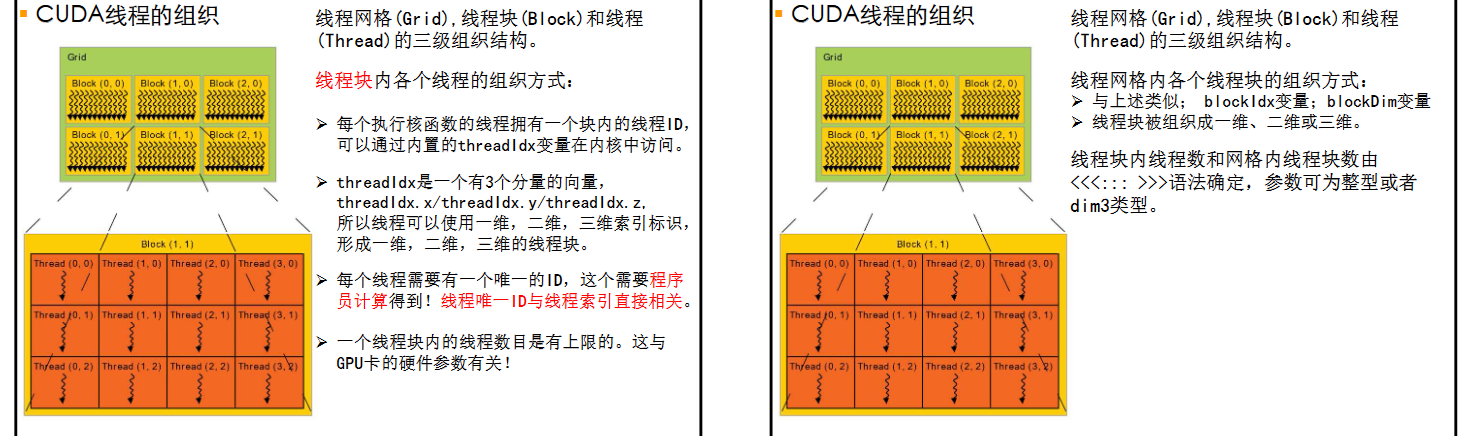
CUDA线程的组织
这部分内容比较重要的就是线程唯一ID的计算,即上文中提到的线程全局索引。本质就是多维数组的索引计算,比较简单。注意区分线程唯一ID和线程索引两个概念。其次就是两类变量,~Dim,一般指各种维度,变量类型是dim3;~Idx,一般指各种索引,类型是unit3。
1 2 struct uint3 {x;y;z;};struct dim3 {x;y;z;};
CPU与GPU之间的数据传输 CUDA早期的CPU与GPU之间的数据传输 cudaMalloc() cudaMalloc() 是 CUDA编程中用于在 GPU 设备上分配内存的函数。它的作用类似于 C/C++ 中的 malloc(),不过它是在 GPU 上分配内存,而不是在 CPU 上。
1 2 __host__ __device__ cudaError_t cudaMalloc (void ** devPtr, size_t size) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <cuda_runtime.h> #include <iostream> int main () int *d_array; size_t size = 100 * sizeof (int ); cudaError_t err = cudaMalloc ((void **)&d_array, size); if (err != cudaSuccess) { std::cerr << "cudaMalloc failed: " << cudaGetErrorString (err) << std::endl; return -1 ; } cudaFree (d_array); return 0 ; }
cudaMallocHost() or cudaHostAlloc() cudaMallocHost() 和 cudaHostAlloc() 是 CUDA 中用于分配主机(CPU)端可固定页内存的函数。固定页内存(pinned memory)是指不能被操作系统交换到磁盘的物理内存,因此可以提供更快的 主机到设备(CPU 到 GPU)的数据传输速度 。
主机的数据分配默认是可分页的。GPU不能直接从可分页的主机内存中访问数据,所以当调用从可分页的主机内存到设备内存的数据传输时,CUDA驱动程序必须首先分配一个临时的分页锁,或“钉住 ”的主机内存页,将主机数据复制到钉住的页中,然后将数据从钉住的页传输到设备内存。
1 2 3 cudaError_t cudaMallocHost (void ** ptr, size_t size) ;cudaError_t cudaHostAlloc (void ** pHost, size_t size, unsigned int flags) ;
unsigned int flags :
这是一个标志位,用于指定分配内存的类型和属性。常用的标志包括:
cudaHostAllocDefault: 默认行为,没有特殊标志。cudaHostAllocPortable: 分配的内存可以在多个 CUDA 上下文中共享。cudaHostAllocMapped: 分配的内存同时也可以映射到设备(GPU)地址空间,这样 GPU 也可以访问这块内存。cudaHostAllocWriteCombined: 分配的内存具有写合并属性,用于减少写入延迟,但读操作速度较慢
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <cuda_runtime.h> #include <iostream> int main () int *h_data; size_t size = 100 * sizeof (int ); cudaError_t err = cudaMallocHost ((void **)&h_data, size); if (err != cudaSuccess) { std::cerr << "cudaMallocHost failed: " << cudaGetErrorString (err) << std::endl; return -1 ; } for (int i = 0 ; i < 100 ; ++i) { h_data[i] = i; } int *d_data; cudaMalloc ((void **)&d_data, size); cudaMemcpy (d_data, h_data, size, cudaMemcpyHostToDevice); cudaFree (d_data); cudaFreeHost (h_data); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <cuda_runtime.h> #include <iostream> int main () int *h_data; size_t size = 100 * sizeof (int ); cudaError_t err = cudaHostAlloc ((void **)&h_data, size, cudaHostAllocMapped); if (err != cudaSuccess) { std::cerr << "cudaHostAlloc failed: " << cudaGetErrorString (err) << std::endl; return -1 ; } for (int i = 0 ; i < 100 ; ++i) { h_data[i] = i; } int *d_data; cudaHostGetDevicePointer (&d_data, h_data, 0 ); cudaFreeHost (h_data); return 0 ; }
cudaMemcpy() cudaMemcpy() 是 CUDA 中用于在主机(CPU)和设备(GPU)之间或者在设备内存之间复制数据的函数。这个函数是 CUDA 编程中非常重要的一部分,因为在实际应用中,数据经常需要在主机和设备之间传输。
1 2 cudaError_t cudaMemcpy (void * dst, const void * src, size_t count, cudaMemcpyKind kind) ;
cudaMemcpyKind kind :
指定数据复制的方向,即从哪里复制到哪里。CUDA 提供了以下几种类型:
cudaMemcpyHostToHost: 主机内存到主机内存的数据复制(不常见)。cudaMemcpyHostToDevice: 主机内存到设备内存的数据复制(常见于将数据从 CPU 传输到 GPU)。cudaMemcpyDeviceToHost: 设备内存到主机内存的数据复制(常见于将计算结果从 GPU 传输回 CPU)。cudaMemcpyDeviceToDevice: 设备内存到设备内存的数据复制(常见于在 GPU 内部进行数据复制)。cudaMemcpyDefault:传输的类型由指针的取值推测处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <cuda_runtime.h> #include <iostream> int main () const int N = 10 ; int h_array[N]; int *d_array; for (int i = 0 ; i < N; ++i) { h_array[i] = i; } cudaMalloc ((void **)&d_array, N * sizeof (int )); cudaMemcpy (d_array, h_array, N * sizeof (int ), cudaMemcpyDefault); cudaMemcpy (h_array, d_array, N * sizeof (int ), cudaMemcpyDefault); for (int i = 0 ; i < N; ++i) { std::cout << h_array[i] << " " ; } cudaFree (d_array); return 0 ; }
cudaMemcpyToSymbol() cudaMemcpyToSymbol() 是 CUDA 中用于将数据从主机(CPU)内存复制到设备(GPU)内存的全局符号(全局变量)或常量内存的函数。这个函数特别用于在设备代码中共享数据,因为它能够将数据复制到设备端的全局变量或常量内存中,从而在 CUDA 核函数(kernel)中访问这些数据。
1 2 cudaError_t cudaMemcpyToSymbol (const void * symbol, const void * src, size_t count, size_t offset = 0 , cudaMemcpyKind kind = cudaMemcpyHostToDevice) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <cuda_runtime.h> #include <iostream> __device__ int deviceVar; __global__ void kernel () { printf ("Value of deviceVar: %d\n" , deviceVar); } int main () int h_value = 42 ; cudaMemcpyToSymbol (deviceVar, &h_value, sizeof (int )); kernel<<<1 , 1 >>>(); cudaDeviceSynchronize (); return 0 ; }
关于symbol :在主机代码 中,deviceVar 是一个符号,用来告诉 CUDA 运行时这个变量在设备内存中的具体位置(地址)。它是一个编译时的符号,用于内存管理和数据复制等操作。在设备代码 中(比如核函数内),deviceVar 作为变量使用时,它表示这个位置上存储的具体数据的值,而不是内存地址。
cudaMemcpyFromSymbol() cudaMemcpyFromSymbol() 是 CUDA中用于将数据从设备端的全局符号(如 __device__ 或 __constant__ 变量)复制回主机内存的函数,这与 cudaMemcpyToSymbol() 相对。
1 2 cudaError_t cudaMemcpyFromSymbol (void * dst, const void * symbol, size_t count, size_t offset = 0 , cudaMemcpyKind kind = cudaMemcpyDeviceToHost) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <cuda_runtime.h> #include <iostream> __device__ int deviceVar; __global__ void kernel () { deviceVar += 10 ; } int main () int h_result; int h_value = 42 ; cudaMemcpyToSymbol (deviceVar, &h_value, sizeof (int )); kernel<<<1 , 1 >>>(); cudaDeviceSynchronize (); cudaMemcpyFromSymbol (&h_result, deviceVar, sizeof (int )); std::cout << "Modified value of deviceVar after kernel execution: " << h_result << std::endl; return 0 ; }
示例代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 int main () const unsigned int N = 1048576 ; const unsigned int bytes = N * sizeof (int ); int *h_a = (int *)malloc (bytes); int *d_a; cudaMalloc ((int **)&d_a, bytes); memset (h_a, 0 , bytes); cudaMemcpy (d_a, h_a, bytes, cudaMemcpyHostToDevice); cudaMemcpy (h_a, d_a, bytes, cudaMemcpyDeviceToHost); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int main () unsigned int nElements = 4 *1024 *1024 ; const unsigned int bytes = nElements * sizeof (float ); float *h_aPageable, *h_aPinned; float *d_a; h_aPageable = (float *)malloc (bytes); checkCuda ( cudaMallocHost ((void **)&h_aPinned, bytes) ); checkCuda ( cudaMalloc ((void **)&d_a, bytes) ); checkCuda ( cudaMemcpy (d_a, h_aPageable, bytes, cudaMemcpyHostToDevice) ); checkCuda ( cudaMemcpy (d_a, h_aPinned, bytes, cudaMemcpyHostToDevice) ); checkCuda ( cudaMemcpy (h_aPageable, d_a, bytes, cudaMemcpyDeviceToHost) ); checkCuda ( cudaMemcpy (h_aPinned, d_a, bytes, cudaMemcpyDeviceToHost) ); cudaFree (d_a); cudaFreeHost (h_aPinned); free (h_aPageable); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <stdio.h> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim; #endif __device__ int d_x = 1 ; __device__ int d_y[2 ]; void __global__ my_kernel (void ) d_y[0 ] += d_x; d_y[1 ] += d_x; printf ("d_x = %d, d_y[0] = %d, d_y[1] = %d.\n" , d_x, d_y[0 ], d_y[1 ]); } int main (void ) int h_y[2 ] = { 10 , 20 }; cudaMemcpyToSymbol (d_y, h_y, sizeof (int ) * 2 ); my_kernel << <1 , 1 >> > (); cudaDeviceSynchronize (); cudaMemcpyFromSymbol (h_y, d_y, sizeof (int ) * 2 ); printf ("h_y[0] = %d, h_y[1] = %d.\n" , h_y[0 ], h_y[1 ]); return 0 ; }
细粒度拷贝 :在数据传输时,你可以选择性地控制要传输的数据量和数据在符号变量中的位置。比如,上面代码中h_y长度为10的话,也只会复制前2个元素。
最新的CUDA的CPU与GPU之间的数据传输 cudaMallocManaged() cudaMallocManaged() 用于分配“统一内存”(Unified Memory)。统一内存是一种内存管理技术,使得 GPU 和 CPU 可以共享同一块内存,而不需要显式地进行内存拷贝操作。
1 2 cudaError_t cudaMallocManaged (void **devPtr, size_t size, unsigned int flags = cudaMemAttachGlobal) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <math.h> #include <cstdio> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __global__ void add (int n, float * x, float * y) int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; } int main (void ) int N = 1 << 20 ; float * x, * y; cudaMallocManaged (&x, N * sizeof (float )); cudaMallocManaged (&y, N * sizeof (float )); for (int i = 0 ; i < N; i++) { x[i] = 1.0f ; y[i] = 2.0f ; } int blockSize = 256 ; int numBlocks = (N + blockSize - 1 ) / blockSize; add << <numBlocks, blockSize >> > (N, x, y); cudaDeviceSynchronize (); cudaFree (x); cudaFree (y); return 0 ; }
统一虚拟地址(UVA) :2014; CUDA 4 引入,将CPU和GPU的内存映射到一个统一的虚拟地址上,这样CPU代码和GPU代码有可能直接访问对方的地址(利用指针). UVA支持零拷贝,锁页内存,分页可迁移内存等 。
统一内存(Unified Memory) : CUDA 6首次引入; 通过创建一个在CPU与GPU之间的管理的内存池实现。
统一内存机制下的__managed__变量
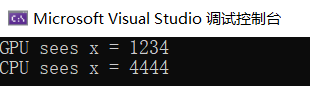
CPU端的全局变量 ——可以 被GPU端共享
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <math.h> #include <cstdio> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __managed__ int x; __global__ void GPU_func () printf ("GPU sees x = %d\n" , x); x = 4444 ; } int main (void ) x = 1234 ; GPU_func << <1 , 1 >> > (); cudaDeviceSynchronize (); printf ("CPU sees x = %d\n" , x); return 0 ; }
CPU端动态分配的局部变量 ——可以 被GPU端共享
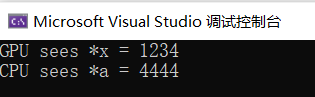
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <math.h> #include <cstdio> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __global__ void GPU_func (int * x) printf ("GPU sees *x = %d\n" , *x); *x = 4444 ; } int main () int * a; cudaMallocManaged (&a, sizeof (int )); *a = 1234 ; GPU_func << < 1 , 1 >> > (a); cudaDeviceSynchronize (); printf ("CPU sees *a = %d\n" , *a); return 0 ; }
不能被__managed__修饰的变量
静态分配的局部变量
函数参数
寄存器变量
使用malloc和new分配的内存
1 int * p = (__managed__ int *)malloc (sizeof (int ));
CUDA中的各级存储资源 registers:寄存器
在GPU片上,执行单元可以以极低的延迟访问这些寄存器。
基本单元是寄存器文件(register file),每个寄存器文件大小为32bit。
寄存器文件数量虽然很多,但是平均分给并行执行的线程时,每个线程拥有的数量就非常有限了。
编程时,每个线程分配的私有变量就会占用寄存器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 __global__ void registerDemo (float *B, float *A, int wA) int aBegin = wA * BLOCK_SIZE * blockIdx.y; int aEnd = aBegin + wA - 1 ; int aEnd = BLOCK_SIZE; for (int a = aBegin; a <= aEnd; a += aStep) { } }
local memory:本地内存 本地内存实际上是位于全局内存中的线程私有存储,用于存放寄存器无法容纳的局部变量。
位于堆栈中,不在寄存器中的所有内容
作用域为特定线程
存储在global内存空间中,速度比寄存器慢很多 对于每个线程,本地内存也是私有的 。
如果寄存器被消耗完,数据将被存储在本地内存中。
如果每个线程用了过多的寄存器,或声明了大型结构体或数组,或者编译期无法确定数组的大小,线程的私有数据就有可能被分配到本地内存中。
一个线程的输入和中间变量将被保存在寄存器或者本地内存中。
shared memory: 共享内存 共享内存(Shared Memory)是CUDA编程中位于每个线程块(Thread Block) 内的存储空间,线程块中的所有线程都可以共享和访问 这块内存。这使得共享内存成为CUDA中一种非常重要的、快速的存储资源,尤其适合需要线程间通信和协同工作的场景。
SM(SM = streaming multiprocessor)中的内存空间
可以配置容量大小,32KB/48KB/64KB等,作用域是线程块
共享内存是GPU片内存储器。它是一个可以被同一block中的所有线程访问的可读写存储器。
访问共享存储器的速度几乎和访问寄存器一样快。是实现线程间通信的延迟最小的有效方法。
共享存储器可用于实现多种功能,如用于保存共用的计数器(例如计算循环迭代次数)或者block的公共结果(例如规约的结果)。
共享内存与L1缓存一般共用存储空间 。
可以是动态 或者静态 分配,声明既可以在kernel内部 也可以作为全局变量 。
动态的使用,若shared Memory的大小在编译器未知的话,可以使用extern关键字修饰
1 extern __shared__ int tile[];
由于其大小编译器未知,故在调用的时候,动态分配,需要传第三个参数 。另外,只有一维数据可以动态使用。
1 kernel<<<grid, block, isize * sizeof (int ) >>>(...)
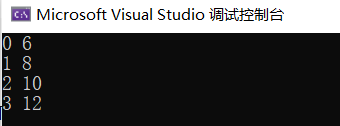
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <math.h> #include <cstdio> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __global__ void example (float *u) int i = threadIdx.x; __shared__ int tmp[4 ]; tmp[i] = u[i]; u[i] = tmp[i] * tmp[i] + tmp[3 - i]; } int main () float host_u[4 ] = { 1 ,2 ,3 ,4 }; for (int i = 0 ; i < 4 ; ++i) printf ("%d %f\n" , i, host_u[i]); float * dev_u; size_t size = 4 * sizeof (float ); cudaMalloc (&dev_u, size); cudaMemcpy (dev_u, host_u, size, cudaMemcpyHostToDevice); example << <1 , 4 >> > (dev_u); cudaMemcpy (host_u, dev_u, size, cudaMemcpyDeviceToHost); for (int i = 0 ; i < 4 ; ++i) printf ("%d %f\n" , i, host_u[i]); cudaFree (dev_u); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <stdio.h> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __global__ void example (float * u) int i = threadIdx.x; extern __shared__ int tmp[]; tmp[i] = u[i]; u[i] = tmp[i] * tmp[i] + tmp[3 - i]; } int main () float host_u[4 ] = { 1 ,2 ,3 ,4 }; float * dev_u; size_t size = 4 * sizeof (float ); for (int i = 0 ; i < 4 ; ++i) printf ("%d %f\n" , i, host_u[i]); cudaMalloc (&dev_u, size); cudaMemcpy (dev_u, host_u, size, cudaMemcpyHostToDevice); example << <1 , 4 , size>>> (dev_u); cudaMemcpy (host_u, dev_u, size, cudaMemcpyDeviceToHost); for (int i = 0 ; i < 4 ; ++i) printf ("%d %f\n" , i, host_u[i]); cudaFree (dev_u); return 0 ; }
constant memory:常量内存
属于全局内存,大小64KB。每个SM拥有8KB的常量内存。
在运行中不变,所有constant变量的值必须在kernel启动前从host设置
只读的地址空间 在Cuda程序中用于存储需要频繁访问的只读参数。当来自同一half-warp的线程访问常量内存中的同一数据时,如果发生缓存命中 ,那么只需要一个周期就可以获得数据。
使用常量内存可以提升运算性能的原因 :
声明:
__constant__修饰使用cudaMemcpyToSymbol(或cudaMemcpy)把数据从主机拷贝到设备GPU中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <stdio.h> #include <cuda_runtime.h> using namespace std;#ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __constant__ int derVar = 100 ; __global__ void xminus (int * a) int i = threadIdx.x; a[i] = derVar + i; } int main () int * h_a = (int *)malloc (4 * 10 ); int * d_a; cudaMalloc (&d_a, 4 * 10 ); cudaMemset (d_a, 0 , 40 ); xminus << <1 , 4 >> > (d_a); cudaMemcpy (h_a, d_a, 4 * 10 , cudaMemcpyDeviceToHost); for (int i = 0 ; i < 4 ; i++) cout << h_a[i] << " " ; cout << endl; return 0 ; }
texture memory:纹理存储器 在 CUDA 编程中,纹理存储器(texture memory)是一种特殊类型的只读内存,旨在优化特定类型的内存访问模式。它用于存储纹理数据,通常用于图像处理和计算机视觉等应用。专门为那些在内存访问模式中存在大量空间局部性 的图形应用而设计,意味着一个线程读取的位置可能与邻近线程读取的位置“非常接近”。(利用空间局部性,便于加速! )
global memory:全局存储器 全局存储器(global memory)是 GPU 中最大的一种存储器类型,它用于存储整个程序执行期间所需的数据。
独立于GPU核心的硬件RAM
GPU绝大多数内存空间都是全局内存
全局内存的IO是GPU上最慢的IO形式(除了访问host端内存)
全局存储器位于显存(占据了显存的绝大部分),CPU、GPU都可以进行读写访问。
整个网格中的任意线程都能读写全局存储器的任意位置。全局存储器能够提供很高的带宽,但同时也具有较高的访存延迟。
可以使用__device__关键字定义的变量分配全局存储器,这个变量应该在所有函数外定义,必须对使用这个变量的host端和device端函数都可见才能成功编译。
在定义__device__变量的同时可以对其赋值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <stdio.h> #include <cuda_runtime.h> using namespace std;#ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __device__ float devU[4 ]; __device__ float devV[4 ]; __global__ void addUV () int i = threadIdx.x; devU[i] += devV[i]; } int main () float hostU[4 ] = { 1 ,2 ,3 ,4 }; float hostV[4 ] = { 5 ,6 ,7 ,8 }; int size = 4 * sizeof (float ); cudaMemcpyToSymbol (devU, hostU, size, 0 , cudaMemcpyHostToDevice); cudaMemcpyToSymbol (devV, hostV, size, 0 , cudaMemcpyHostToDevice); addUV << <1 , 4 >> > (); cudaMemcpyFromSymbol (hostU, devU, size, 0 , cudaMemcpyDeviceToHost); for (int i = 0 ; i < 4 ; ++i) cout << i << ' ' << hostU[i] << '\n' ; return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <stdio.h> #include <cuda_runtime.h> using namespace std;#ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif __global__ void add4f (float * x, float * y) int id = threadIdx.x; x[id] += y[id]; } int main () float hostU[4 ] = { 1 ,2 ,3 ,4 }; float hostV[4 ] = { 5 ,6 ,7 ,8 }; float * devU; float * devV; int size = sizeof (float ) * 4 ; cudaMalloc (&devU, size); cudaMalloc (&devV, size); cudaMemcpy (devU, hostU, size, cudaMemcpyHostToDevice); cudaMemcpy (devV, hostV, size, cudaMemcpyHostToDevice); add4f << <1 , 4 >> > (devU, devV); cudaMemcpy (hostU, devU, size, cudaMemcpyDeviceToHost); for (int i = 0 ; i < 4 ; ++i) cout << i << ' ' << hostU[i] << '\n' ; cudaFree (devV); cudaFree (devU); return 0 ; }
CUDA的流与事件 CUDA流:待执行的CUDA操作的FIFO队列
创建一个CUDA stream
1 cudaError_t cudaStreamCreate (cudaStream_t *stream) ;
1 2 cudaStream_t stream; cudaError_t err = cudaStreamCreate (&stream);
销毁一个 CUDA stream
1 cudaError_t cudaStreamDestroy (cudaStream_t stream) ;
同步等待一个流里的所有操作完成
1 2 cudaError_t cudaStreamSynchronize (cudaStream_t stream) ;
查询一个流里的操作是否已经全部完成
1 2 cudaError_t cudaStreamQuery (cudaStream_t stream) ;
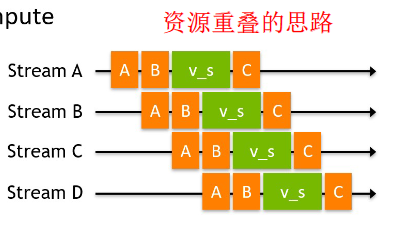
CUDA Streams:一个数据流与执行流重叠的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (int i = 0 ; i < NSTREAMS; ++i) { cudaStreamCreate (&streams[i]); } for (int i = 0 ; i < NSTREAMS; ++i) { int offset = i * eles_per_stream; cudaMemcpyAsync (&d_A[offset], &h_A[offset], eles_per_stream * sizeof (int ), cudaMemcpyHostToDevice, streams[i]); cudaMemcpyAsync (&d_B[offset], &h_B[offset], eles_per_stream * sizeof (int ), cudaMemcpyHostToDevice, streams[i]); vector_sum << <(eles_per_stream + 255 ) / 256 , 256 , 0 , streams[i] >> > (d_A + offset, d_B + offset, d_C + offset, eles_per_stream); cudaMemcpyAsync (&h_C[offset], &d_C[offset], eles_per_stream * sizeof (int ), cudaMemcpyDeviceToHost, streams[i]); } for (int i = 0 ; i < NSTREAMS; ++i) { cudaStreamSynchronize (streams[i]); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <iostream> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif #define N 1024 #define NSTREAMS 4 __global__ void vector_sum (const int * A, const int * B, int * C, int size) { int idx = threadIdx.x + blockIdx.x * blockDim.x; if (idx < size) { C[idx] = A[idx] + B[idx]; } } int main () int * h_A, * h_B, * h_C; int * d_A, * d_B, * d_C; int size = N * sizeof (int ); cudaStream_t streams[NSTREAMS]; int eles_per_stream = N / NSTREAMS; h_A = (int *)malloc (size); h_B = (int *)malloc (size); h_C = (int *)malloc (size); for (int i = 0 ; i < N; ++i) { h_A[i] = i; h_B[i] = i * 2 ; } cudaMalloc (&d_A, size); cudaMalloc (&d_B, size); cudaMalloc (&d_C, size); for (int i = 0 ; i < NSTREAMS; ++i) { cudaStreamCreate (&streams[i]); } for (int i = 0 ; i < NSTREAMS; ++i) { int offset = i * eles_per_stream; cudaMemcpyAsync (&d_A[offset], &h_A[offset], eles_per_stream * sizeof (int ), cudaMemcpyHostToDevice, streams[i]); cudaMemcpyAsync (&d_B[offset], &h_B[offset], eles_per_stream * sizeof (int ), cudaMemcpyHostToDevice, streams[i]); vector_sum << <(eles_per_stream + 255 ) / 256 , 256 , 0 , streams[i] >> > (d_A + offset, d_B + offset, d_C + offset, eles_per_stream); cudaMemcpyAsync (&h_C[offset], &d_C[offset], eles_per_stream * sizeof (int ), cudaMemcpyDeviceToHost, streams[i]); } for (int i = 0 ; i < NSTREAMS; ++i) { cudaStreamSynchronize (streams[i]); } for (int i = 0 ; i < 10 ; ++i) { std::cout << h_C[i] << " " ; } std::cout << std::endl; free (h_A); free (h_B); free (h_C); cudaFree (d_A); cudaFree (d_B); cudaFree (d_C); for (int i = 0 ; i < NSTREAMS; ++i) { cudaStreamDestroy (streams[i]); } return 0 ; }
Stream的调度
Fermi架构最高支持16路并行,但是在物理上,所有stream是被塞进硬件上唯一一个工作队列来调度的。会出现伪依赖 。
伪依赖的情况在Kepler系列里得到了解决,采用的一种叫Hyper-Q的技术,简单粗暴的理解就是,既然工作队列不够用,那就增加好了,于是Kepler上出现了32个工作队列 。该技术也实现了TPC上可以同时运行运算(compute)和图形(graphic)的应用。当然,如果超过32个stream被创建了,依然会出现伪依赖的情况。
在较新的 CUDA Compute Capability(CC)版本中(>=3.5)引入了优先级。
1 2 3 4 cudaError_t cudaStreamCreateWithPriority (cudaStream_t* pStream,unsigned int flags,int priority) ;
CUDA Event 流(Stream) 在 CUDA 中提供了并行执行的机制,但不能简单依赖它们来实现任务的同步和顺序控制。在 CUDA 编程中,事件(Event) 是一种用于测量时间、同步 CUDA 任务的工具。它们是专门设计来追踪 GPU 上某个操作的开始或结束,并可以用来检查任务的完成状态、实现跨流同步等。
创建和销毁事件
记录事件
事件同步
检查事件状态
计算时间
CUDA Stream和event的例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #include <iostream> #include <cuda_runtime.h> #ifdef __INTELLISENSE__ #define __global__ #define __device__ #define __host__ dim3 blockIdx, threadIdx, blockDim, gridDim; #endif #define N (1024*1024) #define FULL_DATA_SIZE N*20 __global__ void kernel (int * a, int * b, int * c) int threadID = blockIdx.x * blockDim.x + threadIdx.x; if (threadID < N) { c[threadID] = (a[threadID] + b[threadID]) / 2 ; } } int main () cudaEvent_t start, stop; float elapsedTime; cudaEventCreate (&start); cudaEventCreate (&stop); cudaEventRecord (start, 0 ); cudaStream_t stream, stream1; cudaStreamCreate (&stream); cudaStreamCreate (&stream1); int * host_a, * host_b, * host_c; int * dev_a, * dev_b, * dev_c; int * dev_a1, * dev_b1, * dev_c1; cudaMalloc ((void **)&dev_a, N * sizeof (int )); cudaMalloc ((void **)&dev_a1, N * sizeof (int )); cudaMalloc ((void **)&dev_b, N * sizeof (int )); cudaMalloc ((void **)&dev_b1, N * sizeof (int )); cudaMalloc ((void **)&dev_c, N * sizeof (int )); cudaMalloc ((void **)&dev_c1, N * sizeof (int )); cudaHostAlloc ((void **)&host_a, FULL_DATA_SIZE * sizeof (int ), cudaHostAllocDefault); cudaHostAlloc ((void **)&host_b, FULL_DATA_SIZE * sizeof (int ), cudaHostAllocDefault); cudaHostAlloc ((void **)&host_c, FULL_DATA_SIZE * sizeof (int ), cudaHostAllocDefault); for (int i = 0 ; i < FULL_DATA_SIZE; i++) { host_a[i] = i; host_b[i] = FULL_DATA_SIZE - i; } for (int i = 0 ; i < FULL_DATA_SIZE; i += 2 * N) { cudaMemcpyAsync (dev_a, host_a + i, N * sizeof (int ), cudaMemcpyHostToDevice, stream); cudaMemcpyAsync (dev_b, host_b + i, N * sizeof (int ), cudaMemcpyHostToDevice, stream); cudaMemcpyAsync (dev_a1, host_a + i + N, N * sizeof (int ), cudaMemcpyHostToDevice, stream1); cudaMemcpyAsync (dev_b1, host_b + i + N, N * sizeof (int ), cudaMemcpyHostToDevice, stream1); kernel << <N / 1024 , 1024 , 0 , stream >> > (dev_a, dev_b, dev_c); kernel << <N / 1024 , 1024 , 0 , stream1 >> > (dev_a, dev_b, dev_c1); cudaMemcpyAsync (host_c + i, dev_c, N * sizeof (int ), cudaMemcpyDeviceToHost, stream); cudaMemcpyAsync (host_c + i + N, dev_c1, N * sizeof (int ), cudaMemcpyDeviceToHost, stream1); } cudaStreamSynchronize (stream); cudaStreamSynchronize (stream1); cudaEventRecord (stop, 0 ); cudaEventSynchronize (stop); cudaEventElapsedTime (&elapsedTime, start, stop); std::cout << "消耗时间: " << elapsedTime << std::endl; cudaFreeHost (host_a); cudaFreeHost (host_b); cudaFreeHost (host_c); cudaFree (dev_a); cudaFree (dev_a1); cudaFree (dev_b); cudaFree (dev_b1); cudaFree (dev_c); cudaFree (dev_c1); cudaStreamDestroy (stream); cudaStreamDestroy (stream1); return 0 ; }