PyTorch 入门
环境配置
示例代码:分类 MNIST 数据集
环境配置
是需要PyCharm+Conda+Pytorch的。B站视频讲解(视频讲解是重点,下面内容不重要)
Conda
Conda分为Miniconda和Anaconda,有一定的区别,但是应该不重要。
Conda主要用于管理Python环境和包的工具,为用户提供了一种简化的方式来安装、管理和切换 Python 版本及其相关的包。它们的核心功能是帮助用户创建隔离的环境,以便在不同的项目中使用不同的包和依赖项,而不会产生冲突。
简单来说,就是那个b Python的包太多了,然后配那个b环境麻烦的要死。而Conda提供一个虚拟环境,把不同的项目隔开,从来减少上述问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| conda env list # 查看现有的环境列表
# 为了加快Python包的下载速度,添加国内镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda activate [环境名] # 切换到对应环境
conda list # 查看环境内可用的软件包
pip list # 查看环境下下载的软件包
conda install [包名] # 在对应的环境下下载软件包
conda remove [包名] # 删除包
conda remove --help # 查看使用方法
|
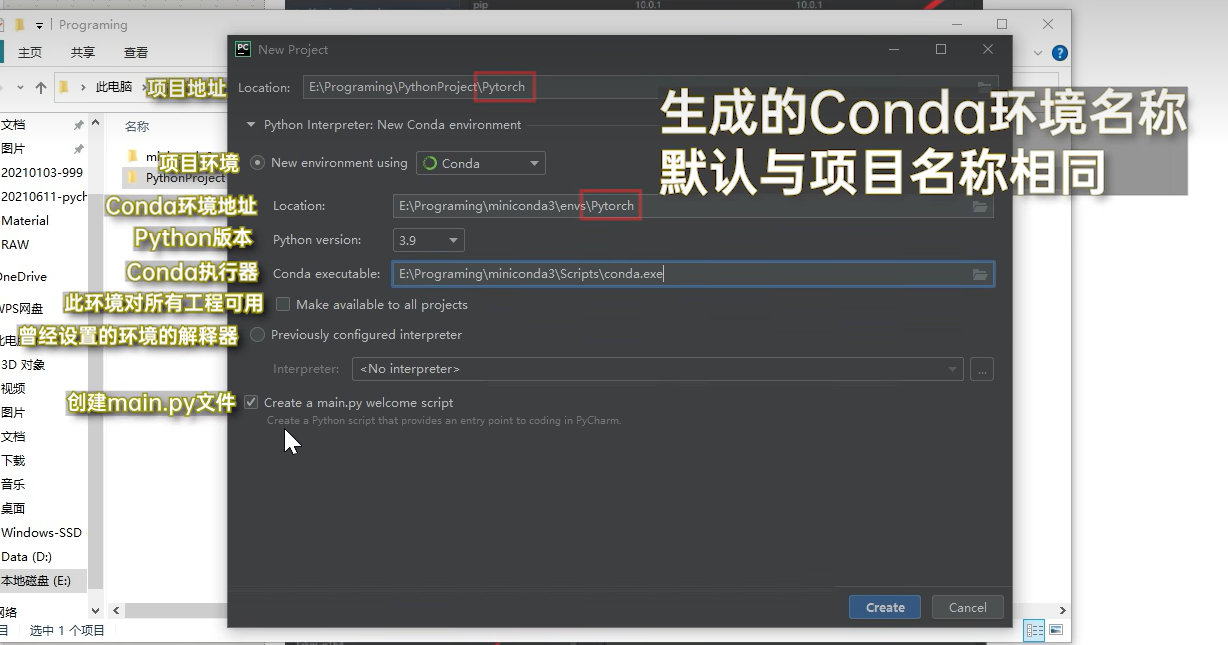
PyCharm
创建使用Conda环境的Python项目。
PyTorch
PyTorch官网:https://pytorch.org/get-started/previous-versions/
使用nvidia-smi查看电脑显卡的cuda版本。
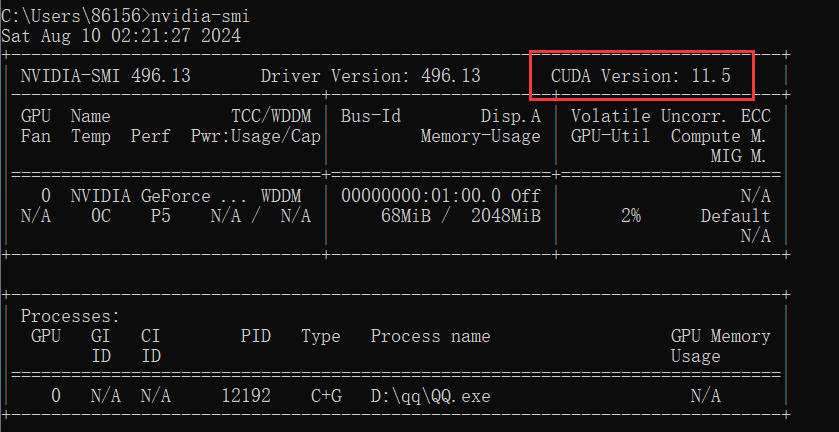
在过去版本中找到小于等于的,然后在对应Conda环境下运行安装命令。
1
2
| # CUDA 11.3
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
|
最后在Anaconda里有个done说明成功了。
1
2
3
4
5
6
7
8
9
10
11
12
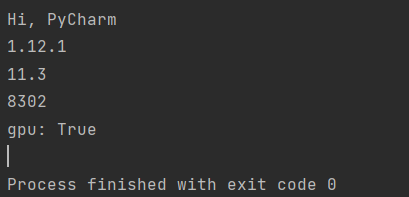
| import torch
def print_hi(name):
print(f'Hi, {name}')
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print('gpu:', torch.cuda.is_available())
if __name__ == '__main__':
print_hi('PyCharm')
|
示例代码:分类 MNIST 数据集
一个完整的训练脚本一般包括数据加载、模型定义、训练和评估。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
batch_size = 64
learning_rate = 0.01
epochs = 5
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = SimpleNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
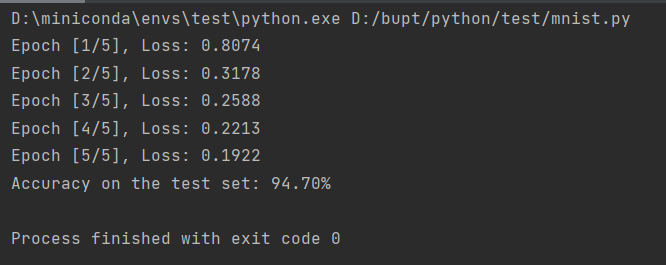
print(f"Epoch [{epoch+1}/{epochs}], Loss: {running_loss/len(train_loader):.4f}")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on the test set: {100 * correct / total:.2f}%")
|
软件包导入
1
2
3
4
5
| import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
|
torch:PyTorch 的核心,处理张量和自动微分。
torch.nn:用于构建和定义神经网络模型。
torch.optim:用于优化模型参数,提供多种优化算法。
DataLoader:用于批量加载数据,特别适合大规模数据集。
torchvision:处理图像数据的工具包,提供数据集、预处理和预训练模型。
设置超参数
1
2
3
4
|
batch_size = 64
learning_rate = 0.01
epochs = 5
|
学习率控制着优化器在每次迭代时应该调整模型参数的幅度。学习率的设置需要在模型训练的速度与稳定性之间找到一个平衡。过大的学习率虽然可能使模型快速收敛,但容易导致训练不稳定;过小的学习率虽然训练稳定,但速度可能非常慢。常见的初始学习率范围在 0.001 到 0.1 之间。
数据加载和预处理
1
2
3
4
5
6
7
8
9
10
11
|
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
|
通常,原始图像数据以 PIL(Python Imaging Library)图像对象或 NumPy 数组的形式存在。
transforms.ToTensor():将 PIL 图像或 NumPy 数组转换为 PyTorch 的 torch.Tensor 对象,同时将像素值从 [0, 255] 归一化到 [0, 1] 之间。
transforms.Normalize((0.1307,), (0.3081,)):对数据进行标准化处理,将每个像素值调整为均值为 0、标准差为 1 的分布。这里的 0.1307 和 0.3081 是在整个数据集上预先计算好的全局均值和标准差,通常在MNIST数据集中使用。
标准化后,数据将具有均值为 0,标准差为 1 的分布。这使得模型在处理数据时,各个特征在同一个尺度上,有利于梯度下降法的有效应用。标准化可以防止输入数据的范围过大或过小,避免在神经网络训练过程中出现梯度消失或爆炸的问题。
定义简单的神经网络模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = SimpleNet()
|
x.view(-1, 28 * 28):将输入的图像展平为一个 784 维的向量,以便输入到全连接层。
-1 表示自动推断批次的大小(batch size),因此如果输入是多个图像,将每张图像展平成 784 维的向量。- 例如,如果输入是一个形状为
(batch_size, 1, 28, 28) 的四维张量,那么经过 view 操作后,形状将变为 (batch_size, 784)。
ReLU: 将输入的负值置为 0,正值保持不变。return x:返回最终的输出,即每个类别的得分。通常在后续步骤中,会将这个输出传递给 softmax 函数,以转换为概率分布,从而得到最终的分类结果。
定义损失函数和优化器
1
2
3
|
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
|
训练模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {running_loss/len(train_loader):.4f}")
|
测试模型
1
2
3
4
5
6
7
8
9
10
11
12
13
|
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on the test set: {100 * correct / total:.2f}%")
|